


La crescente domanda di servizi cloud, unitamente alla necessità di sostituire l’hardware obsoleto e raggiungere costi operativi più ridotti, sta portando le aziende ad adottare un’Infrastruttura Iperconvergente (HCI) nel data center.
L’iperconvergenza è entrata quindi nel mercato dell’IT come risposta ad esigenze di flessibilità e scalabilità dei sistemi informativi a costi accessibili e senza complessità di gestione.
In questo articolo mostrerò come creare un Cluster Iperconvergente Proxmox a 3 nodi illustrando il funzionamento dell’HA (Hight Avaibility) delle VM (Virtual Machine) mediante la configurazione avanzata di Ceph.
SOFTWARE UTILIZZATO PER IL CLUSTER PROXMOX
Proxmox VE 8.1.10
Ceph versione Reef 18.2.2
HARDWARE UTILIZZATO PER IL CLUSTER PROXMOX
Per la creazione dell’ambiente sono stati utilizzati 3 mini PC con le seguenti caratterstiche:
MODELLO MINI PC: KingnovyPC 12th Gen Fanless Mini PC senza ventola
PROCESSORE: Processore Inter N100 di 12a generazione basato su Alder Lake
ETHERNET: 2 x RJ45 LAN
PORTE VARIE: 2 x DB9 COM, 4 x USB, 2 x HDMI, 1 x DP
RAM: 32 GB – Corsair Memoria per laptop Vengeance SODIMM da 32 GB (1×32 GB) DDR4 3200 MHz CL22
DISCO PRIMARIO: 4 TB – SAMSUNG Memorie MZ-V9P4T0C 990 PRO SSD Interno con Dissipatore di Calore
DISCO SECONDARIO: 4 TB – Samsung 870 QVO 4 TB SATA 2.5 Inch Internal Solid State Drive (SSD) (MZ-77Q4T0)
RISORSE DEI SINGOLI HOST
Di seguito la configurazione di ogni singolo Host:
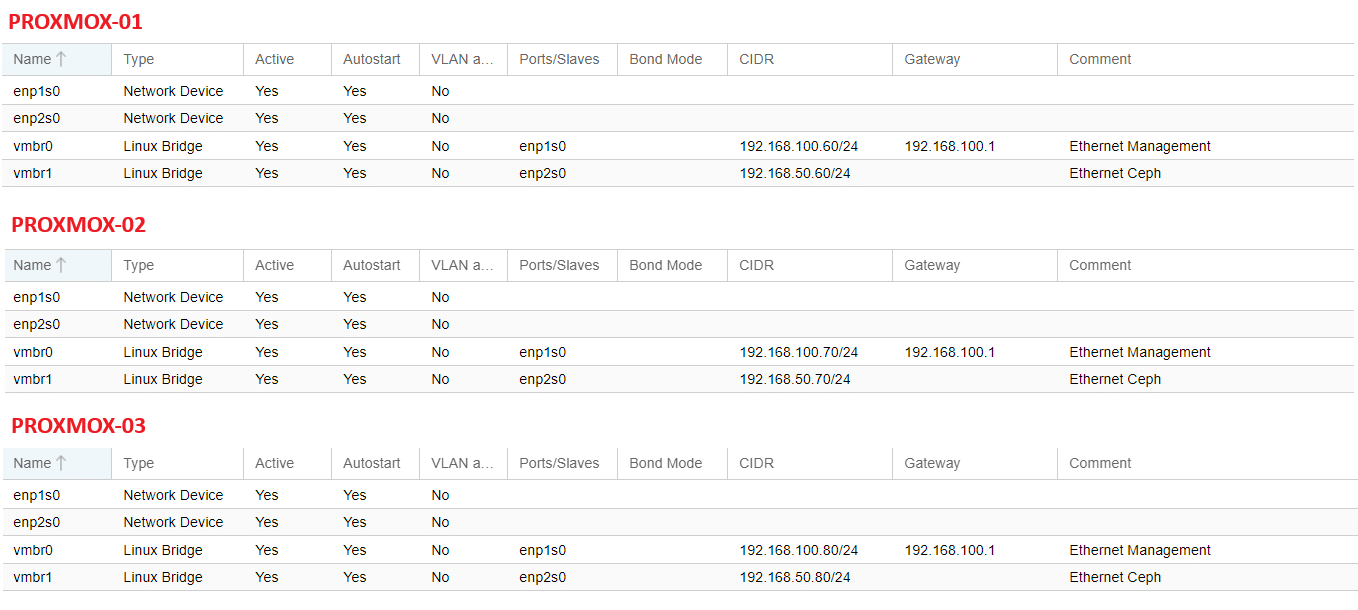
NOME: proxmox-01
IP MANAGEMENT: 192.168.100.60
IP CEPH: 192.168.50.60
DISCO PRIMARIO: 4TB
DISCO SECONDARIO: 4TB
NOME: proxmox-02
IP MANAGEMENT: 192.168.100.70
IP CEPH: 192.168.50.70
DISCO PRIMARIO: 4TB
DISCO SECONDARIO: 4TB
NOME: proxmox-03
IP MANAGEMENT: 192.168.100.80
IP CEPH: 192.168.50.80
DISCO PRIMARIO: 4TB
DISCO SECONDARIO: 4TB
CONFIGURAZIONE DEL NETWORK
Al fine di garantire un l’alta affidabilità e quindi sfruttare al massimo le caratteristiche di Ceph, come già anticipato, abbiamo deciso di separare la Cluster Network e la Public Network.
Public network: è la rete dedicata alla gestione del monitoring di Ceph, ovvero tutti i dati e controlli che servono ai nodi per capire in che “stato” si trovano.
Cluster network: è la rete dedicata alla gestione degli OSD e al traffico heartbeat, ovvero è la rete che si occupa di sincronizzare tutti i “dati” dei dischi virtuali delle VM.
Tuttavia, non è obbligatorio separare il traffico in due reti ma fortemente consigliato in produzione dove le grandezze del cluster iniziano ad essere considerevoli.
Esistono due motivazioni principali per usare due reti separate:
Prestazioni: quando i demoni OSD Ceph gestiscono le repliche dei dati sul cluster, il traffico di rete può introdurre latenza al traffico dei Ceph client creando anche un possibile disservizio.Inoltre anche il traffico per il monitoring sarebbe rallentato impedendo una visione veritiera dello stato del cluster. Ricordiamo che il recupero e il riequilibrio del cluster, in caso di guasto, deve essere fatto nel minore tempo possibile, ovvero i PG (Placement Group) devono essere spostati dagli OSD in modo rapido per recuperare una situazione critica.
Sicurezza: un attacco DoS (Denial of Service) potrebbe saturare le risorse di rete per la gestione delle repliche e questo comporterebbe anche ad un rallentamento (o addirittura un completo arresto) del traffico di monitoring.
Ricordo che i Ceph monitor permettono ai Client Ceph di leggere e scrivere i dati sul cluster: possiamo immaginare dunque cosa potrebbe succedere a fronte di una congestione della rete usata per il Monitoring. Separando le due reti invece, il traffico di monitoring non verrebbe minimamente congestionato.
Si consiglia fortemente, per ragioni di sicurezze ed efficienza, di non collegare a Internet la Cluster Network e la Public network: mantenendole quindi nascoste dall’esterno e separate da tutte le altre reti.
Nelle immagini di seguito viene riportata la configurazione delle schede di rete per i 3 host Proxmox, ovvero i 3 nodi del cluster.
Per visualizzare la configurazione andare sul nodo desiderato, poi cliccare sul pulsante network.
CREAZIONE DEL CLUSTER
Ciò richiederà almeno 3 server Proxmox fisici. È possibile creare un cluster con due, ma l’HA non funzionerà se sono presenti meno di 3 nodi in un cluster.
Collegarsi via GUI al primo Server Proxmox
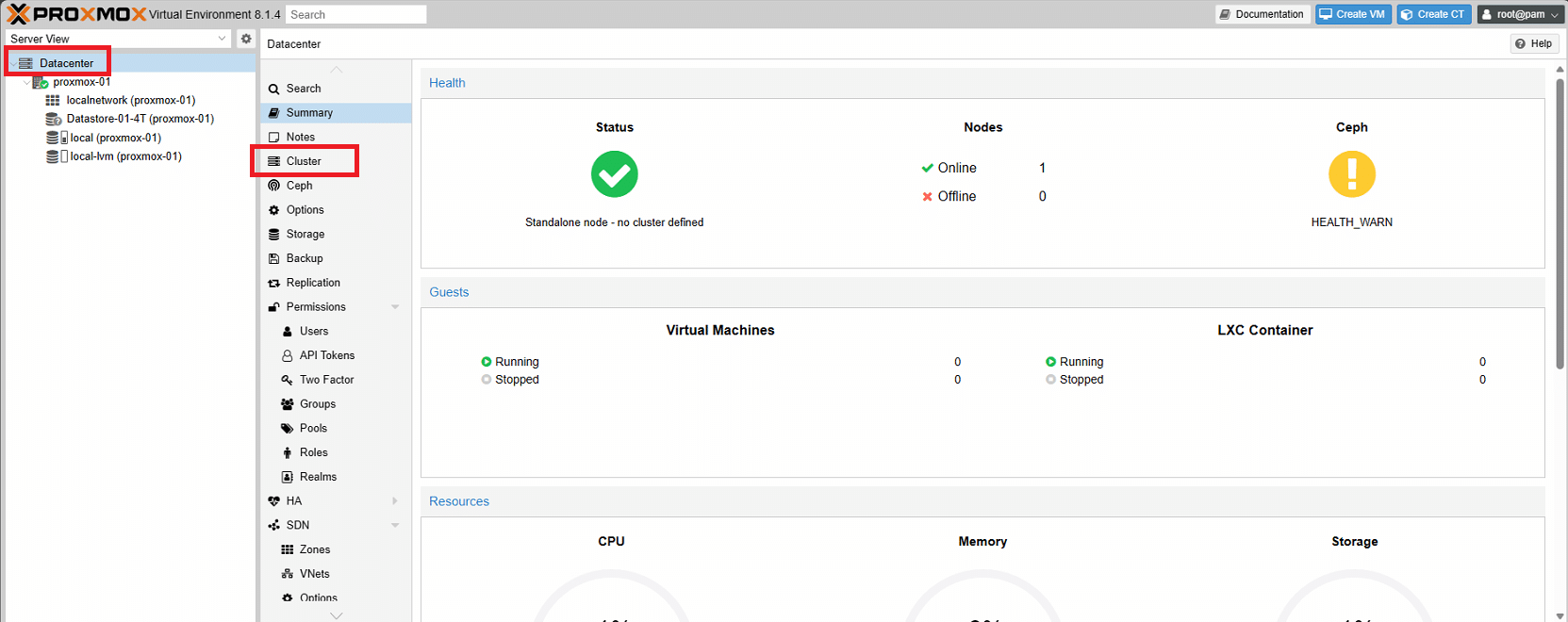
Cliccare sulla scheda Datacenter quindi selezionare Cluster
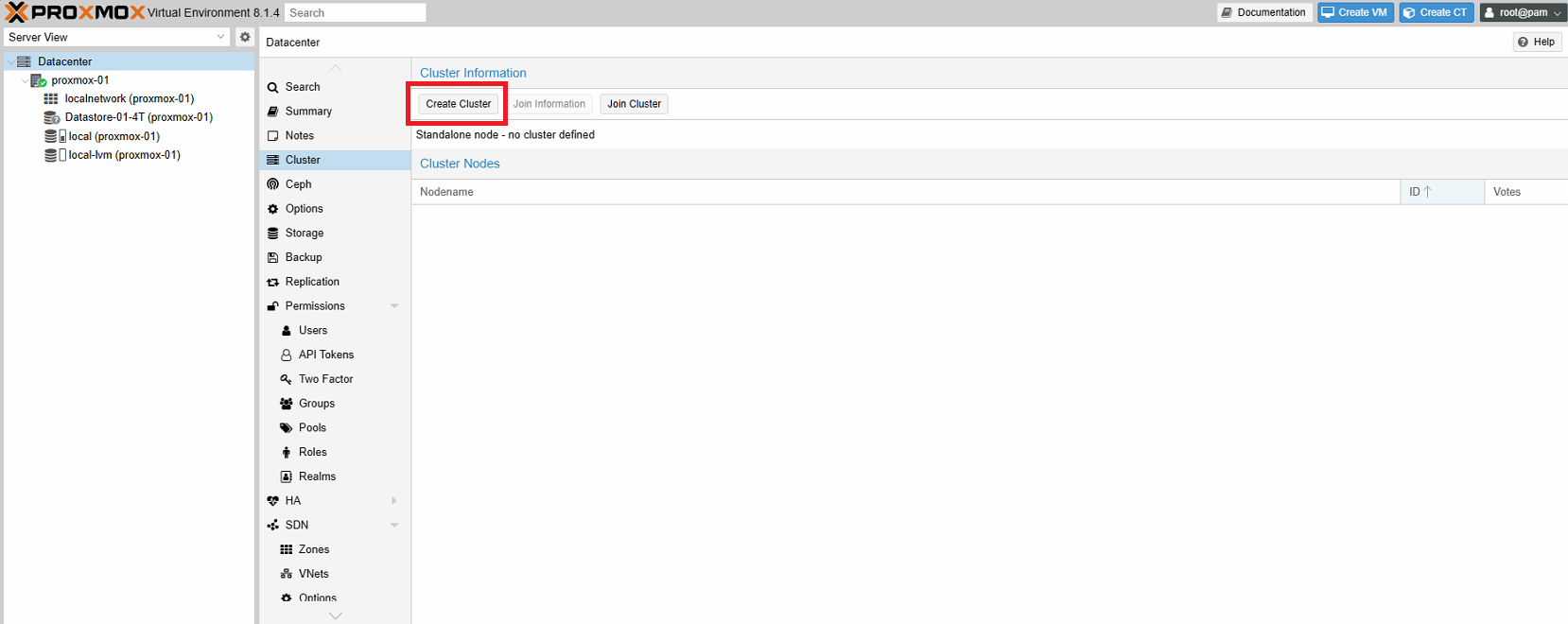
Cliccare su Create Cluster
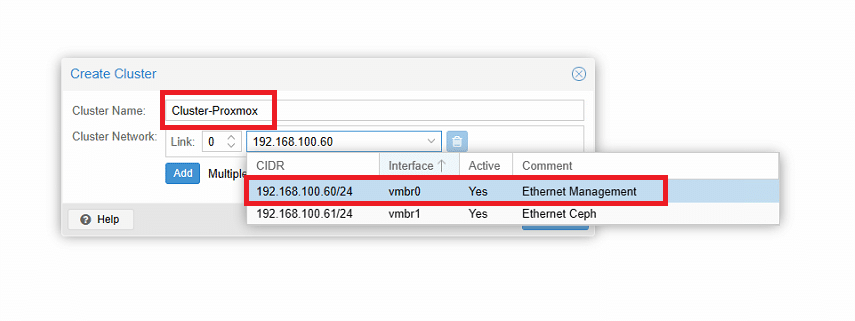
Inserire il nome del cluster e selezionare la scheda di rete da attribuire al Cluster Network
ATTENZIONE: il nome del cluster non deve contenere spazi
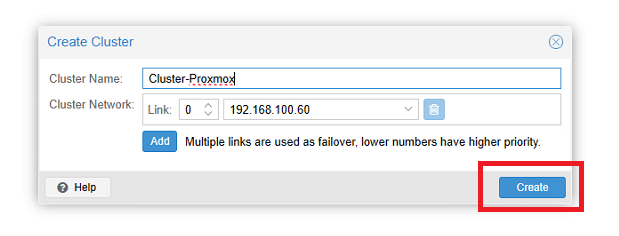
Cliccare Create
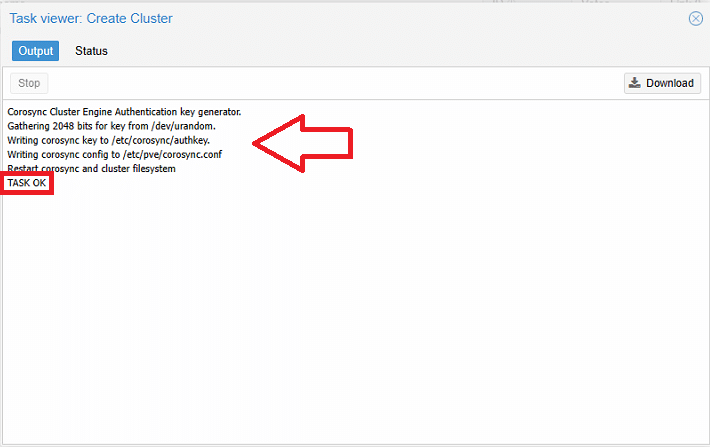
Se è tutto OK dovremmo vedere una schermata come quella sovrastante
A questo punto collegarsi via web gui al secondo nodo Proxmox e posizionarsi su Datacenter
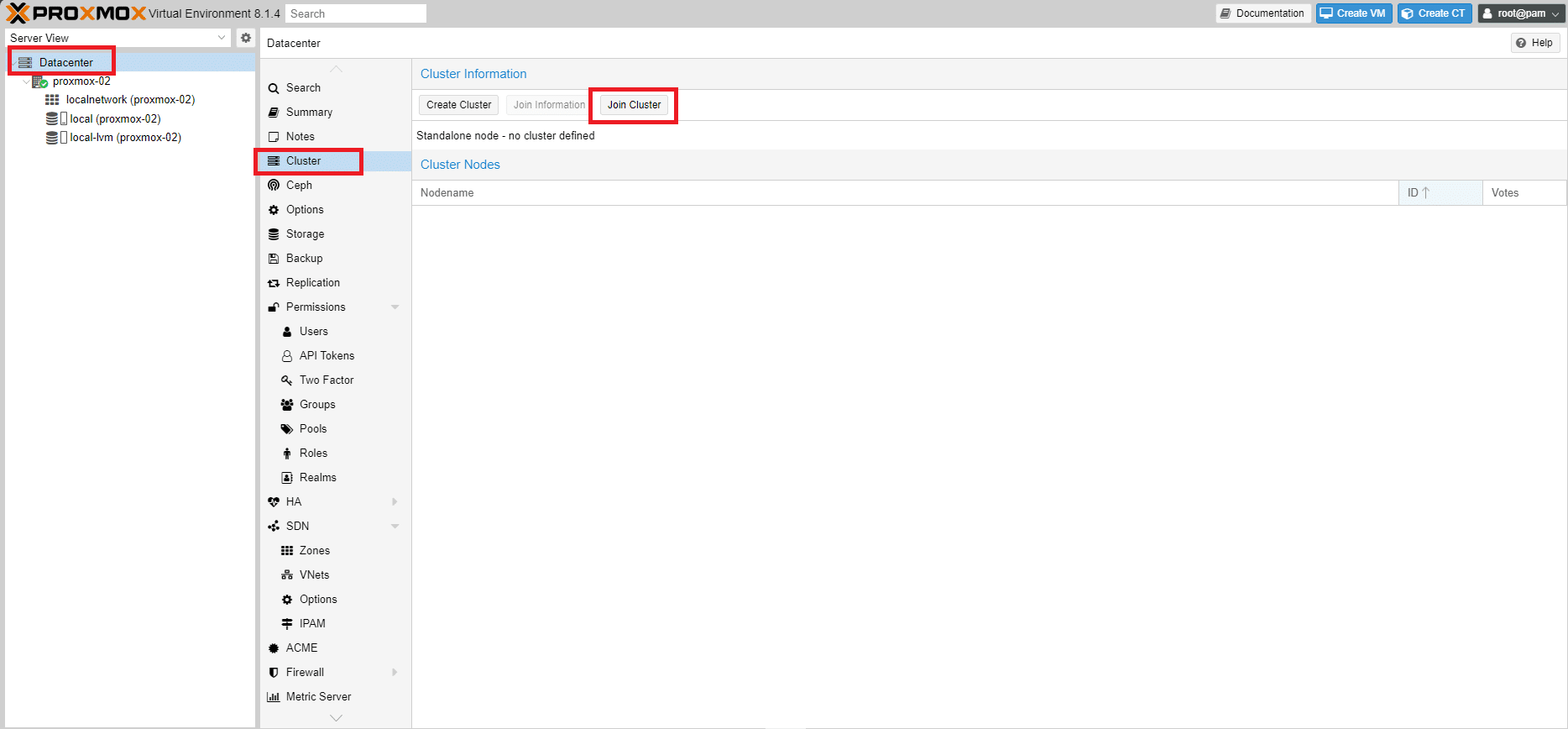
Dopo aver selezionato Datacenter cliccare su Cluster quindi Join Cluster
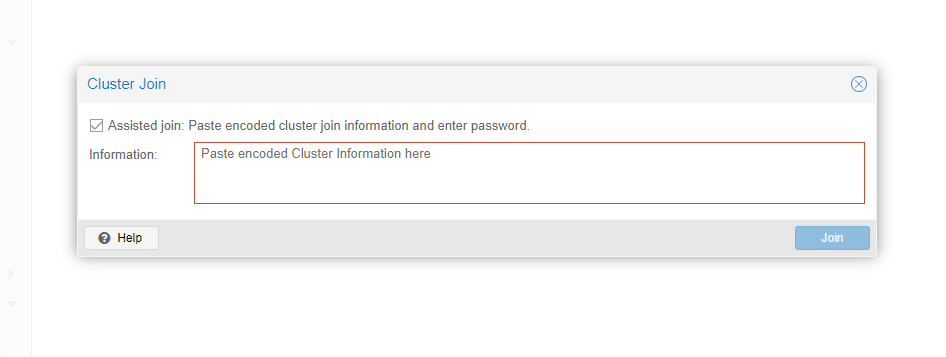
In questa finestra va inserita l’informazione relativa al cluster creato sul primo nodo.
Collegarsi al Primo nodo Proxmox
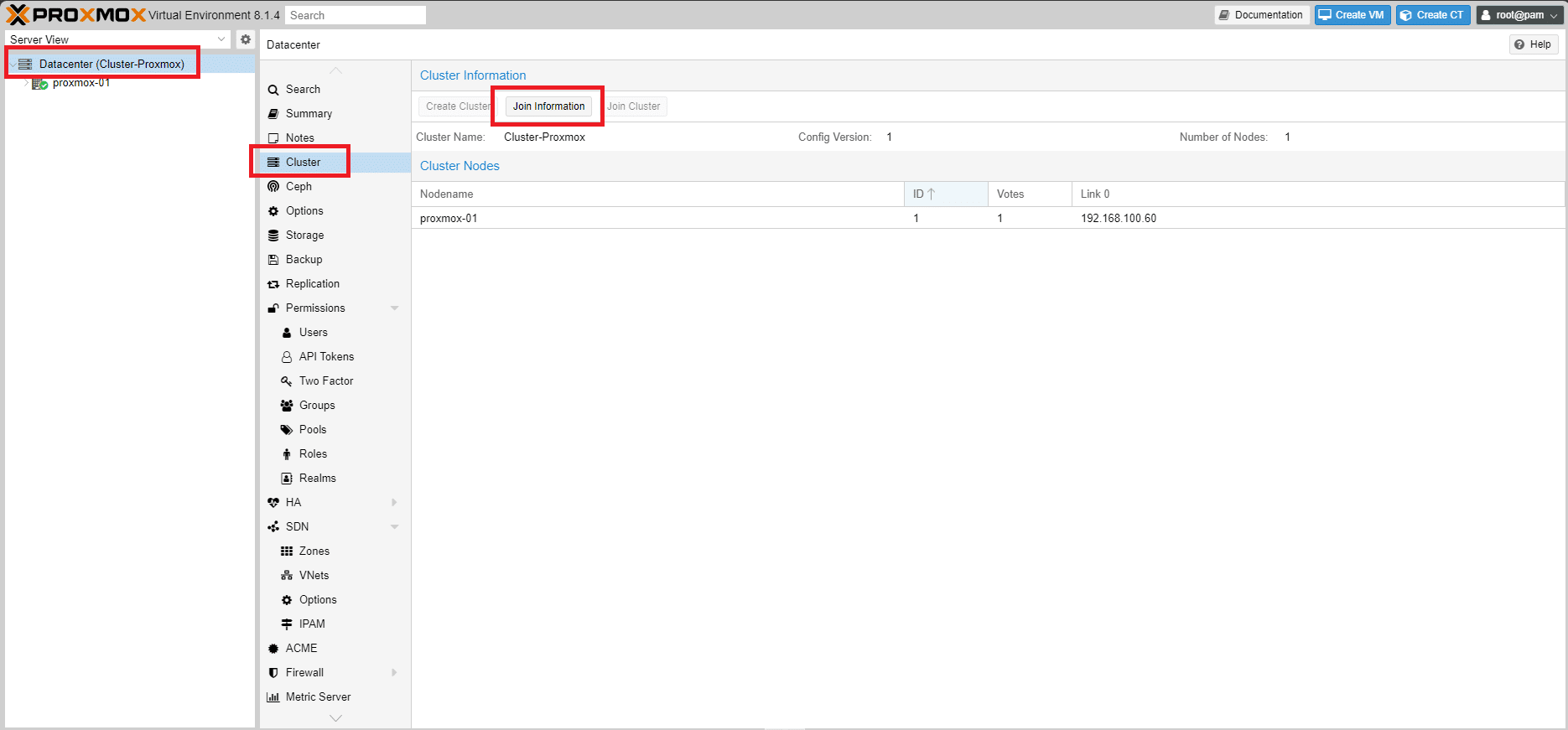
Cliccare su Datacenter quindi Cluster e selezionare Join Information come mostrato nell’immagine sovrastante
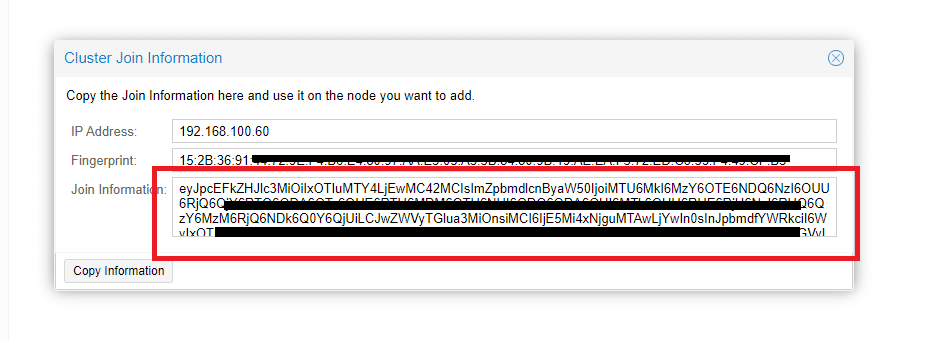
Copiare tutto il contenuto di Join Information come evidenziato nell’immagine sovrastante
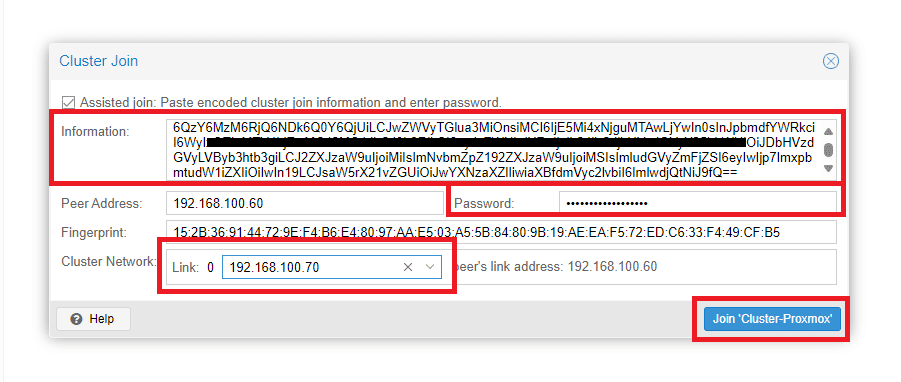
Incollare il codice copiato, inserire la password di root del primo nodo Proxmox quindi selezionare l’interfaccia da utlizzare come Cluster Network.
Cliccare Join Cluster-Proxmox
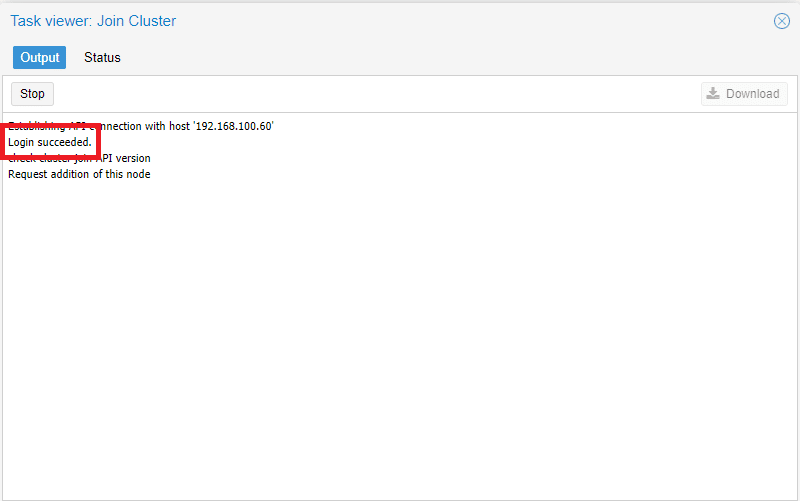
Se è andato tutto a buon fine dovremmo vedere una schermata come quella sovrastante
Eseguire la stessa procedura anche per il terzo nodo Proxmox
Il Cluster Proxmox sarà raggiungibile su uno di questi 3 indirizzi (essendo un Cluster è indifferente quale).
192.168.100.60:8006
192.168.100.70:8006
192.168.100.80:8006
CONFIGURAZIONE DEL SERVER NTP
Lo stack del cluster Proxmox VE fa molto affidamento sul fatto che tutti i nodi hanno l’ora esattamente sincronizzata. Anche alcuni altri componenti, come Ceph, non funzioneranno correttamente se l’ora locale su tutti i nodi non è sincronizzata.
La sincronizzazione temporale tra i nodi può essere ottenuta utilizzando il “Network Time Protocol” (NTP). A partire da Proxmox VE 7, chrony viene utilizzato come demone NTP predefinito, mentre Proxmox VE 6 utilizza systemd-timesyncd. Entrambi sono preconfigurati per utilizzare una serie di server pubblici.
In alcuni casi, potrebbe essere preferibile utilizzare server NTP non predefiniti. Ad esempio, se i nodi Proxmox VE non hanno accesso alla rete Internet pubblica a causa di regole firewall restrittive bisogna configurare i server NTP locali e dire al demone NTP di utilizzarli.
Aprire quindi il file di configurazione di chrony /etc/chrony/chrony.conf con il comando:
|
0 |
nano /etc/chrony/chrony.conf
|
Dovremmo visualizzare un output come mostrato di seguito:
|
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
GNU nano 7.2 /etc/chrony/chrony.conf
# Welcome to the chrony configuration file. See chrony.conf(5) for more
# information about usable directives.
# Include configuration files found in /etc/chrony/conf.d.
confdir /etc/chrony/conf.d
# Use Debian vendor zone.
pool 2.debian.pool.ntp.org iburst
# Use time sources from DHCP.
sourcedir /run/chrony-dhcp
# Use NTP sources found in /etc/chrony/sources.d.
sourcedir /etc/chrony/sources.d
# This directive specify the location of the file containing ID/key pairs for
# NTP authentication.
keyfile /etc/chrony/chrony.keys
# This directive specify the file into which chronyd will store the rate
# information.
driftfile /var/lib/chrony/chrony.drift
# Save NTS keys and cookies.
ntsdumpdir /var/lib/chrony
# Uncomment the following line to turn logging on.
#log tracking measurements statistics
# Log files location.
logdir /var/log/chrony
# Stop bad estimates upsetting machine clock.
maxupdateskew 100.0
# This directive enables kernel synchronisation (every 11 minutes) of the
# real-time clock. Note that it can't be used along with the 'rtcfile' directive.
rtcsync
# Step the system clock instead of slewing it if the adjustment is larger than
# one second, but only in the first three clock updates.
makestep 1 3
# Get TAI-UTC offset and leap seconds from the system tz database.
# This directive must be commented out when using time sources serving
# leap-smeared time.
leapsectz right/UTC
|
L’NTP configurato di default è pool 2.debian.pool.ntp.org iburst
Per configurare un server NTP interno basta aggiungere la seguente stringa nel file di configurazione:
server NTP-Server.local iburst
ATTENZIONE: al posto di NTP-Server.local inserire l’FQDN del server NTP oppure l’indirizzo IP
Salvare e chiudere il file di configurazione
Riavviare il servizio chronyd con il comando:
|
0 |
systemctl restart chronyd
|
Per verificare i server NTP configurati sul server Proxmox eseguire il comando:
|
0 |
chronyc sources
|
Dovremmo visualizzare tutti i server NTP configurati
Per verificare che l’orario sia corretto eseguire il comando:
|
0 |
timedatectl |
Se è tutto corretto dovremmo visualizzare un output come mostrato di seguito:
|
0
1
2
3
4
5
6
|
Local time: Mon 2024-04-29 21:08:30 CEST
Universal time: Mon 2024-04-29 19:08:30 UTC
RTC time: Mon 2024-04-29 19:08:30
Time zone: Europe/Rome (CEST, +0200)
System clock synchronized: yes
NTP service: active
RTC in local TZ: no
|
Ovviamente eseguire la configurazione del server NTP su tgutti i nodi del cluster Proxmox.
INSTALLAZIONE E CONFIGURAZIONE DI CEPH
Ceph Storage è una soluzione di storage open source altamente scalabile, progettata per ospitare dispositivi di storage a oggetti, dispositivi a blocchi e storage di file all’interno dello stesso cluster. In sostanza, Ceph è un sistema unificato che mira a semplificare l’archiviazione e la gestione di grandi volumi di dati.
Un cluster di storage Ceph è costituito da diversi tipi di daemon: daemon OSD Ceph (OSD è l’acronimo di Object Storage Daemon), Ceph Monitors, Ceph MDS (Metadata Server o cluster di server di metadati) e altri. Ogni tipo di demone svolge un ruolo distinto nel funzionamento del sistema di archiviazione.
I daemon OSD Ceph gestiscono l’archiviazione e la replica dei dati, memorizzando i dati su diversi dispositivi nel cluster. I Ceph Monitor, d’altra parte, tengono traccia dello stato del cluster, mantenendo una mappa dell’intero sistema, inclusi tutti i dati e i demoni.
Ceph MDS, o server di metadati, sono specifici di Ceph File System. Memorizzano i metadati per il file system, consentendo ai daemon OSD Ceph di concentrarsi esclusivamente sulla gestione dei dati.
Una caratteristica chiave dello storage Ceph è il suo metodo di posizionamento intelligente dei dati. Un algoritmo chiamato CRUSH (Controlled Replication Under Scalable Hashing) decide dove archiviare e come recuperare i dati, evitando qualsiasi singolo punto di errore e fornendo in modo efficace uno storage fault-tolerant.
ATTENZIONE: la configurazione seguente prevede la Cluster Network e la Pulbic Network sulla stessa VLAN e con l’utilizzo della scheda di rete. In ambienti di Produzione è consigliabile utilizzare VLAN e schede di rete differenti.
Collagarsi alla Web Gui di Proxmox
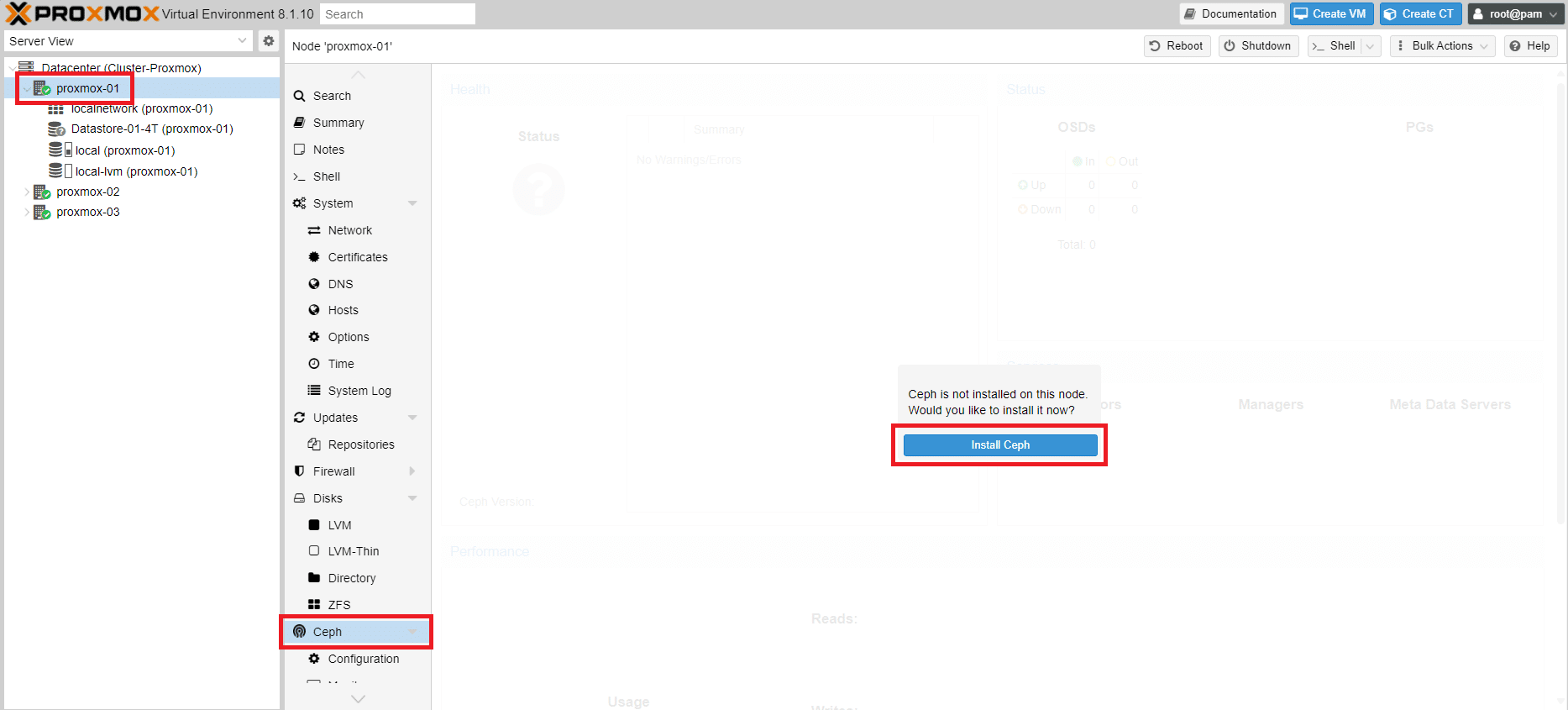
Selezionare il Nodo proxmox-01 quindi Ceph e Cliccare su Install Ceph
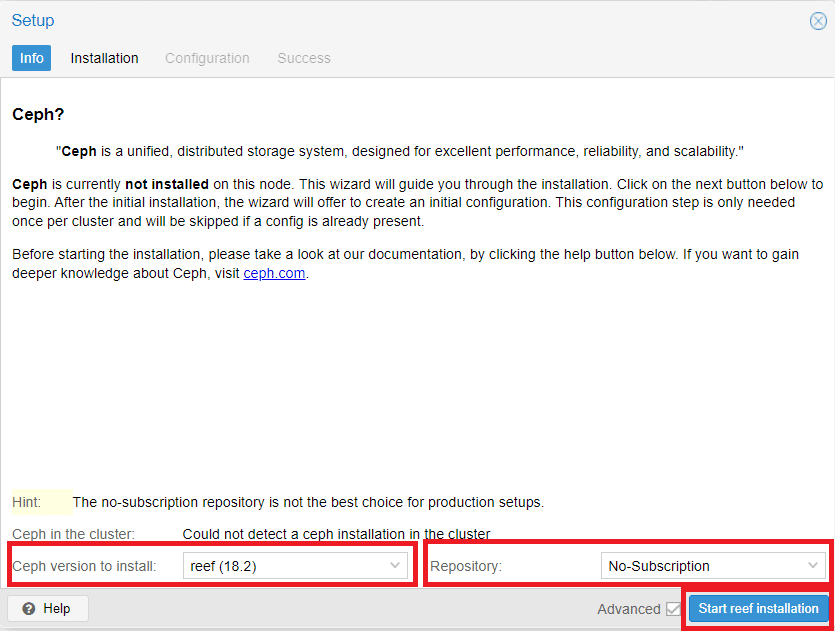
Selezionare la versione Ceph da installare quindi la Repository.
Cliccare Start reef Installation
ATTENZIONE: durante la stesura di questo articolo l’ultima versione disponibile di Ceph è la versione reef (18.2). Per quanto riguarda la Subscription Proxmox consiglia di utilizzare la versione Enterprise per ambienti di Produzione
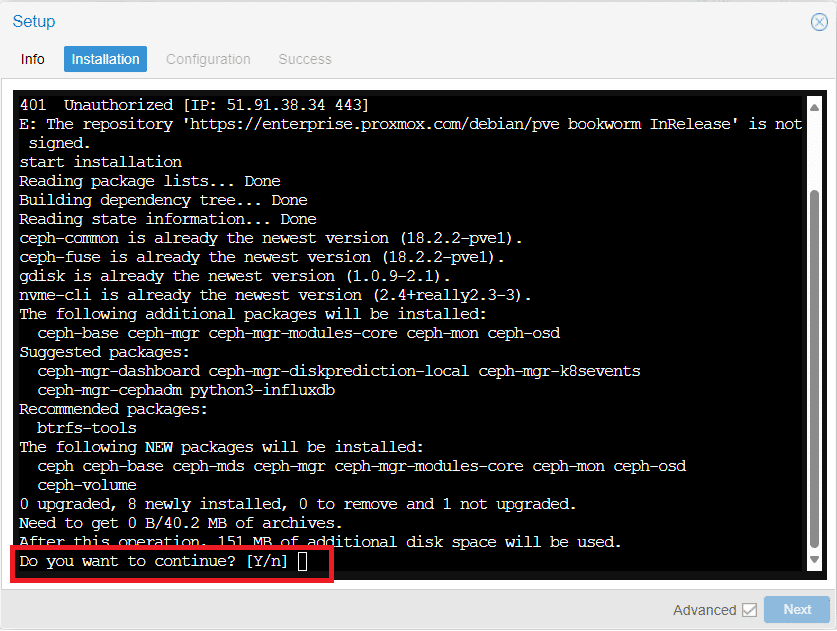
Cliccare Y per proseguire con l’installazione
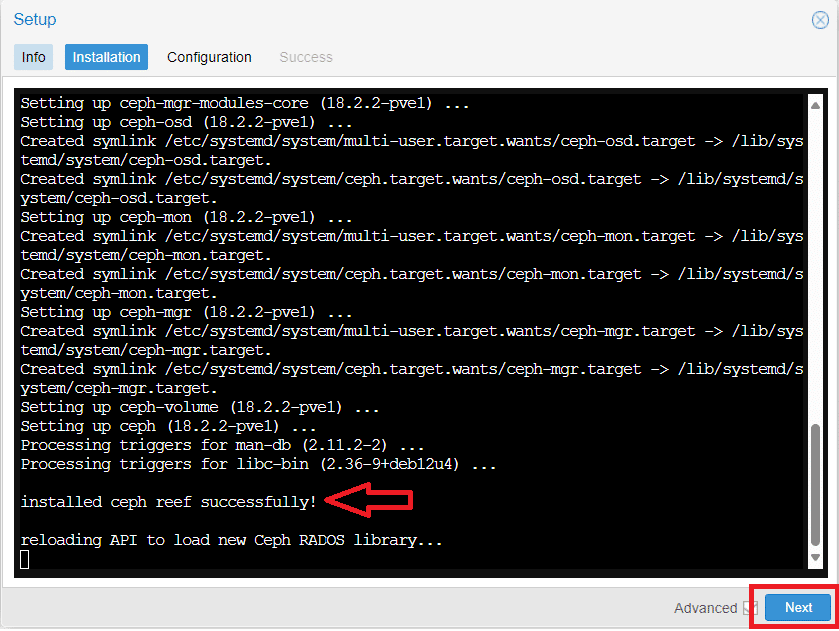
Verificare che ci sia scritto installed ceph reef successfully! come mostrato nell’immagine sovrastante e cliccare Next per proseguire
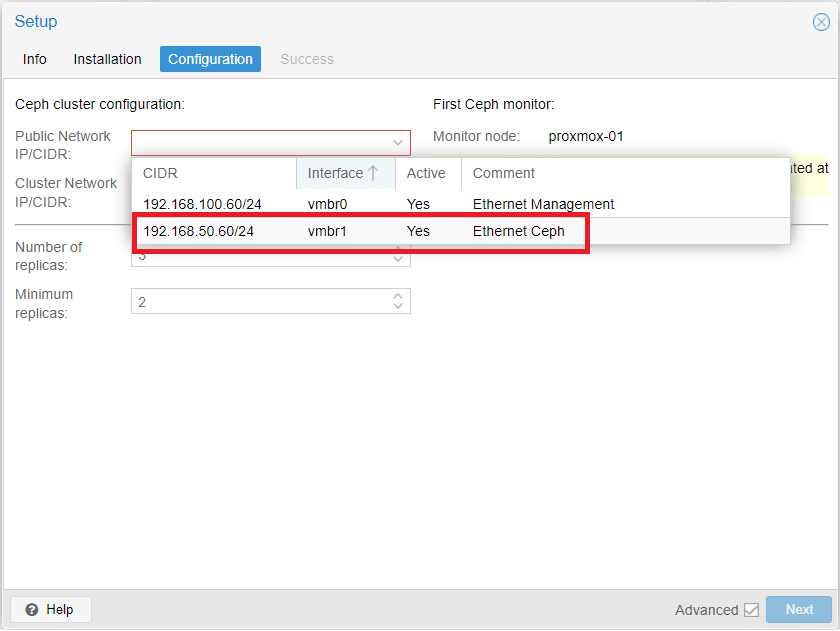
Configurare la Public Network selezionando dal menù a tendina l’interfaccia creata in precedenza denominata vmbr1
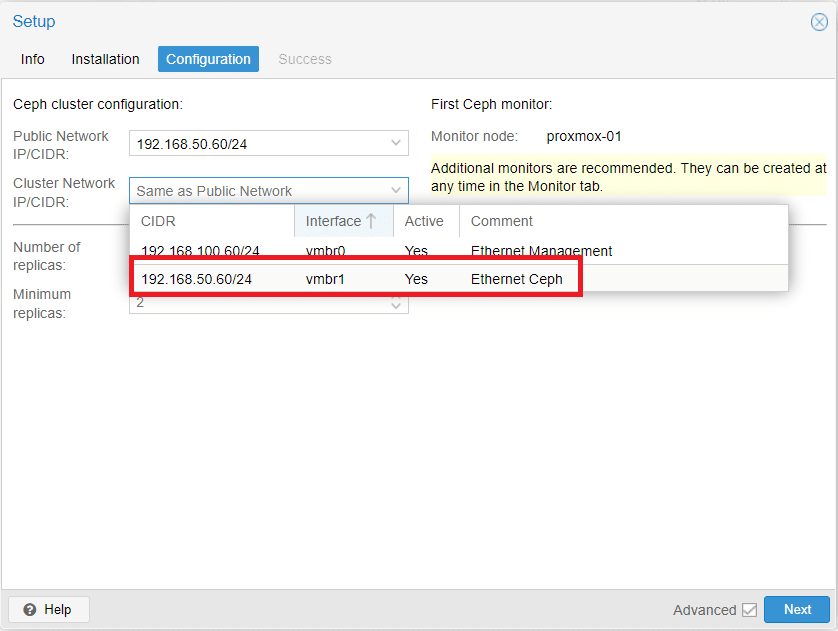
Impostare la Cluster Network selezionando dal menù a tendina l’interfaccia creata in precedenza denominata vmbr1
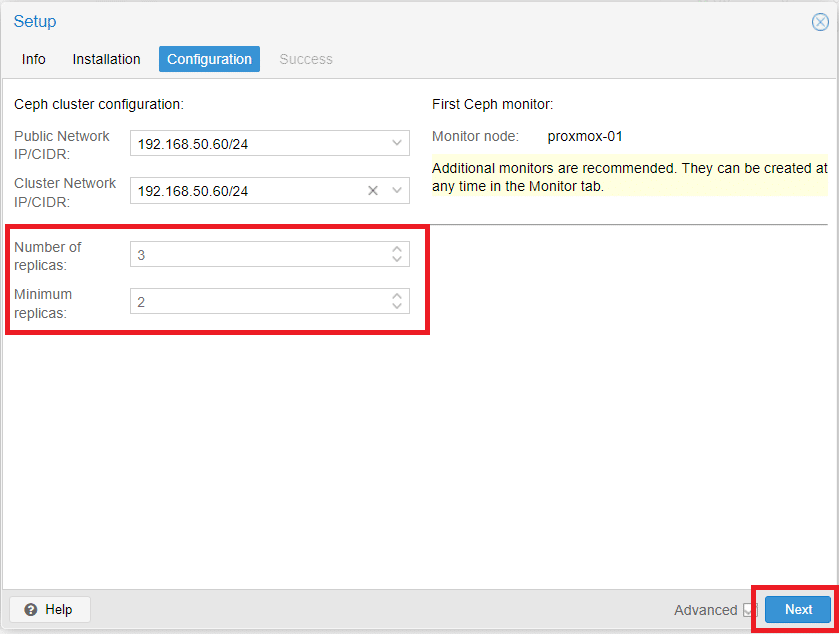
Configurare il numero di repliche e il numero minimo di repliche quindi cliccare Next per proseguire
Cliccare Finish per terminare l’installazione di Ceph
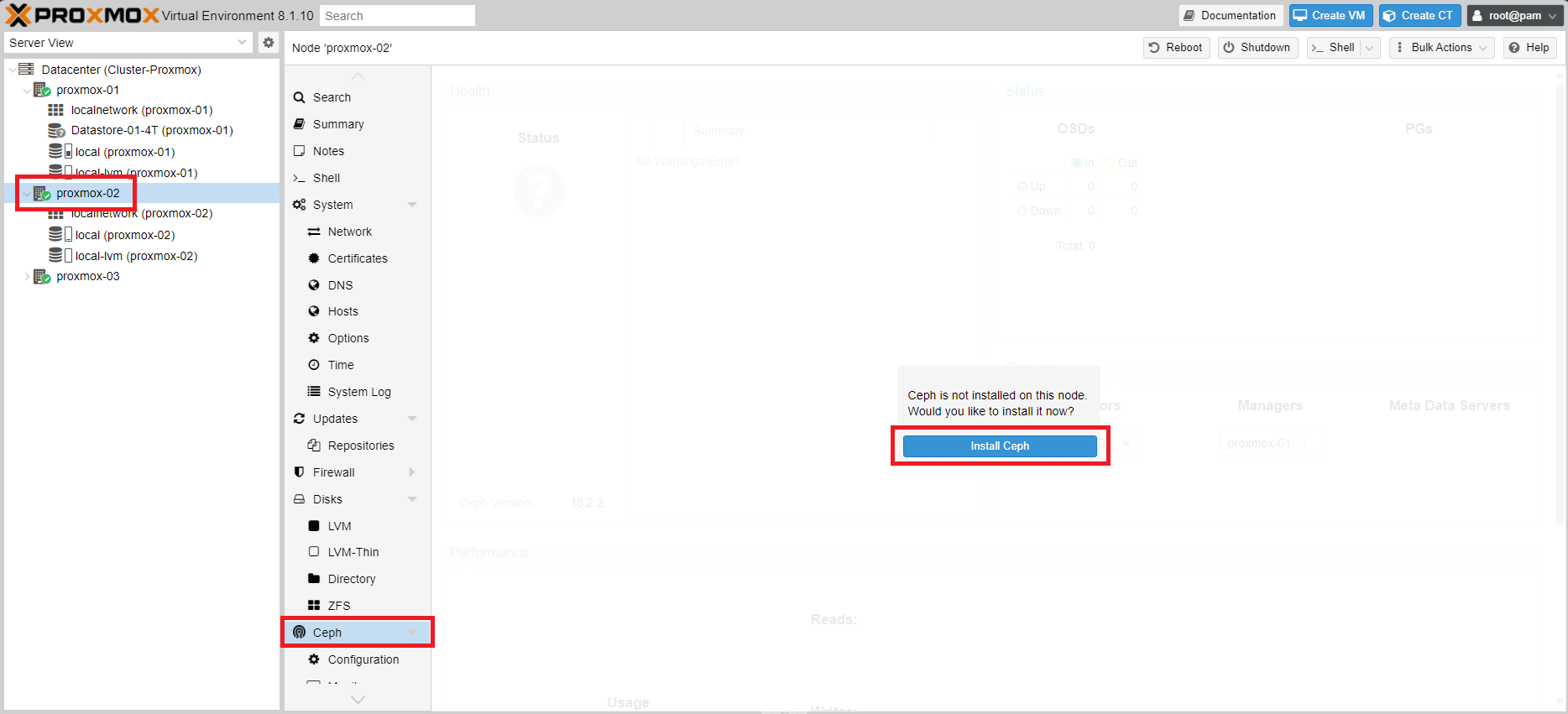
Selezionare il Nodo proxmox-02 quindi Ceph e Cliccare su Install Ceph
Selezionare la versione Ceph da installare quindi la Repository.
Cliccare Start reef Installation
Cliccare Y per proseguire con l’installazione
Verificare che ci sia scritto installed ceph reef successfully! come mostrato nell’immagine sovrastante e cliccare Next per proseguire
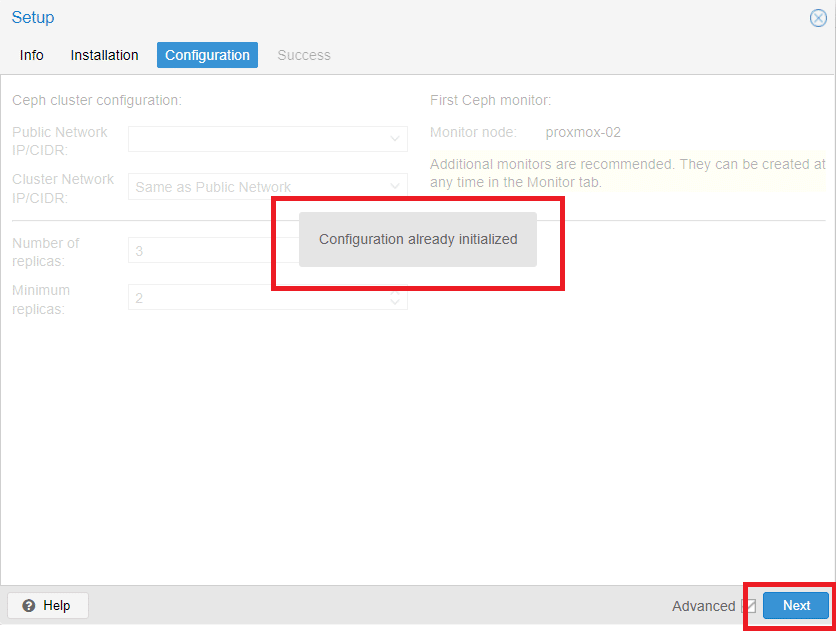
Dovremmo visualizzare il messaggio Configuration already initialized come mostrato nell’immagine sovrastante.
Cliccare Next per proseguire
Cliccare Finish per terminare l’installazione di Ceph
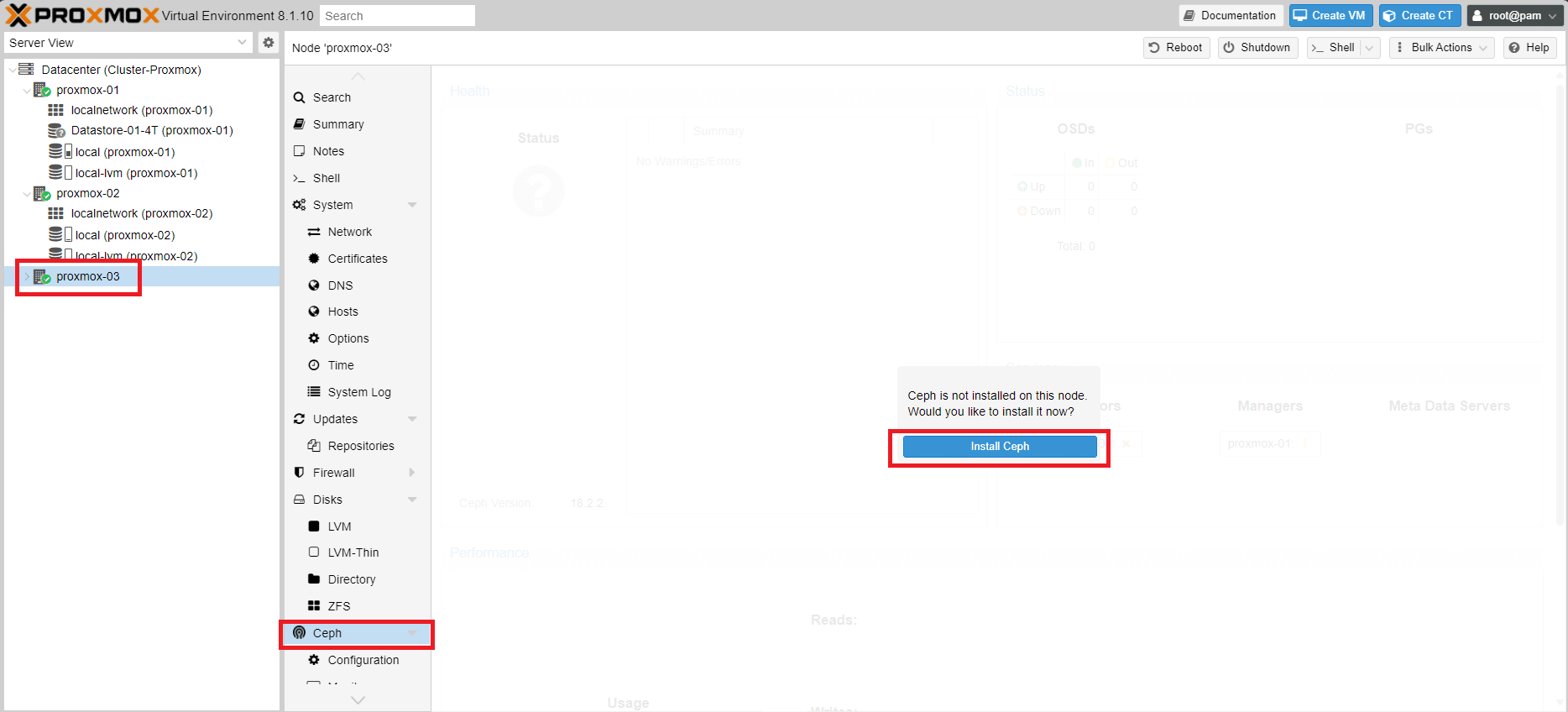
Selezionare il Nodo proxmox-03 quindi Ceph e Cliccare su Install Ceph
Selezionare la versione Ceph da installare quindi la Repository.
Cliccare Start reef Installation
Cliccare Y per proseguire con l’installazione
Verificare che ci sia scritto installed ceph reef successfully! come mostrato nell’immagine sovrastante e cliccare Next per proseguire
Dovremmo visualizzare il messaggio Configuration already initialized come mostrato nell’immagine sovrastante.
Cliccare Next per proseguire
Cliccare Finish per terminare l’installazione di Ceph
CONFIGURAZIONE DEI DEMONI OSD CEPH
I daemon Ceph OSD e i monitor Ceph sono fondamentali per il funzionamento del cluster di storage Ceph. I daemon OSD gestiscono l’archiviazione, il recupero e la replica dei dati sui dispositivi di storage, mentre Ceph Monitor gestisce la mappa del cluster, tenendo traccia dei nodi del cluster attivi e non riusciti.
È necessario assegnare diversi OSD Ceph per gestire l’archiviazione dei dati e mantenere la ridondanza dei dati.
L’elemento OSD (Object Storage Daemon) è uno layer software che si preoccupa di storicizzare i dati, gestire le repliche, il recovery e il rebalancing dei dati. Inoltre fornisce tutte le informazioni ai Ceph Monitor e Ceph Manager.
E’ consigliabile associare un OSD per ogni disco (ssd o hdd): in questo modo un singolo OSD gestirà solo il disco associato.
Tramite la Web Gui di proxmox selezionare il nodo proxmox-01
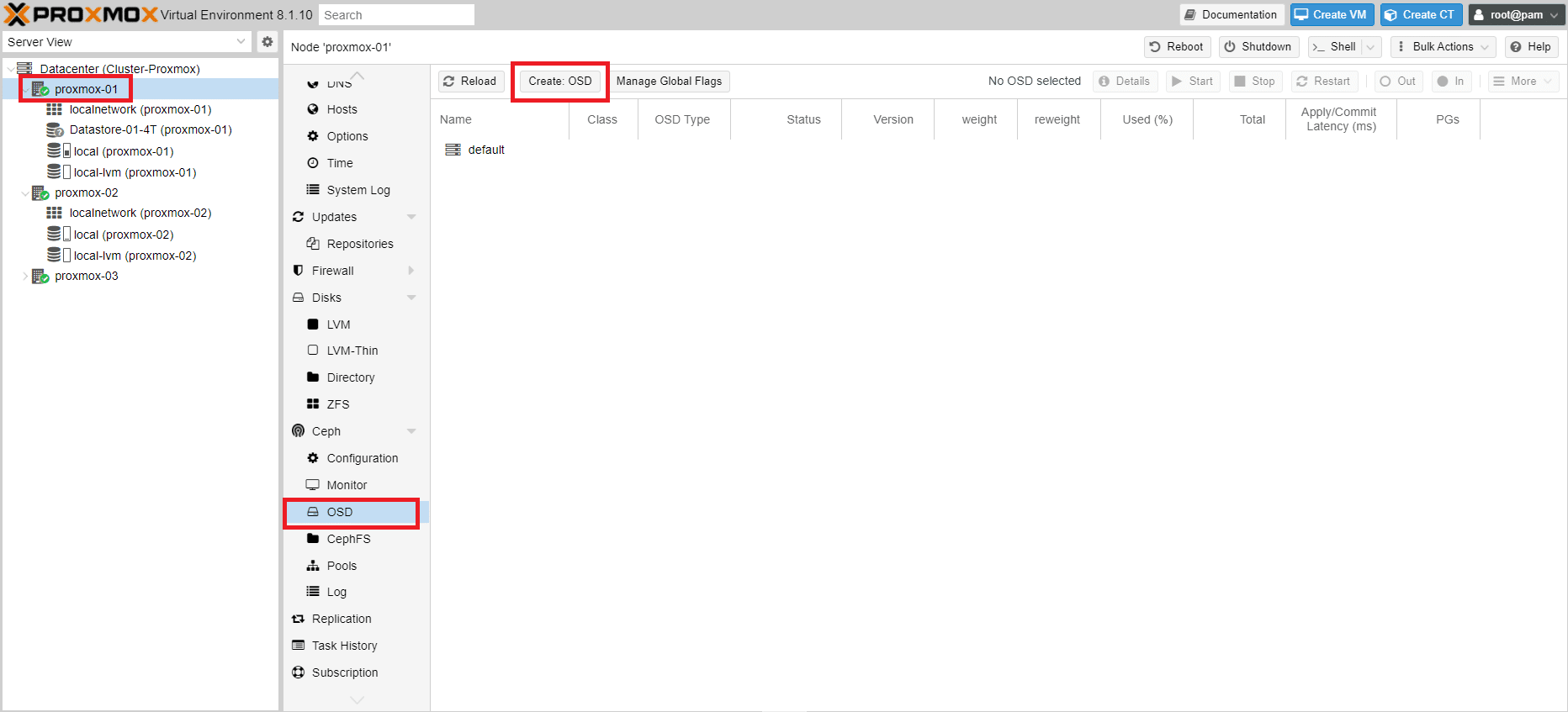
Quindi selezionare sotto il menù Ceph la voce OSD. Cliccare quindi Create: OSD
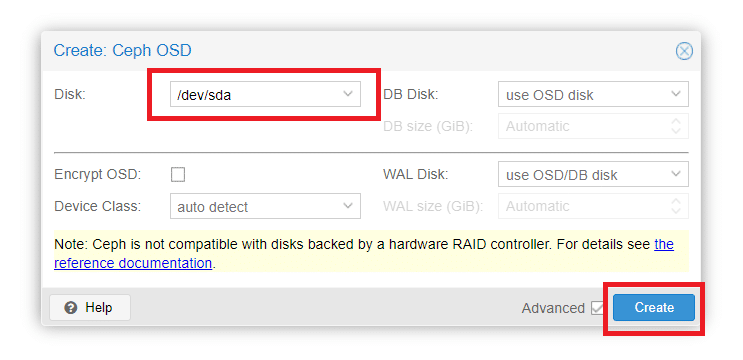
Selezionare il disco (nel mio caso l’unico disco presente è /dev/sda) quindi cliccare su Create
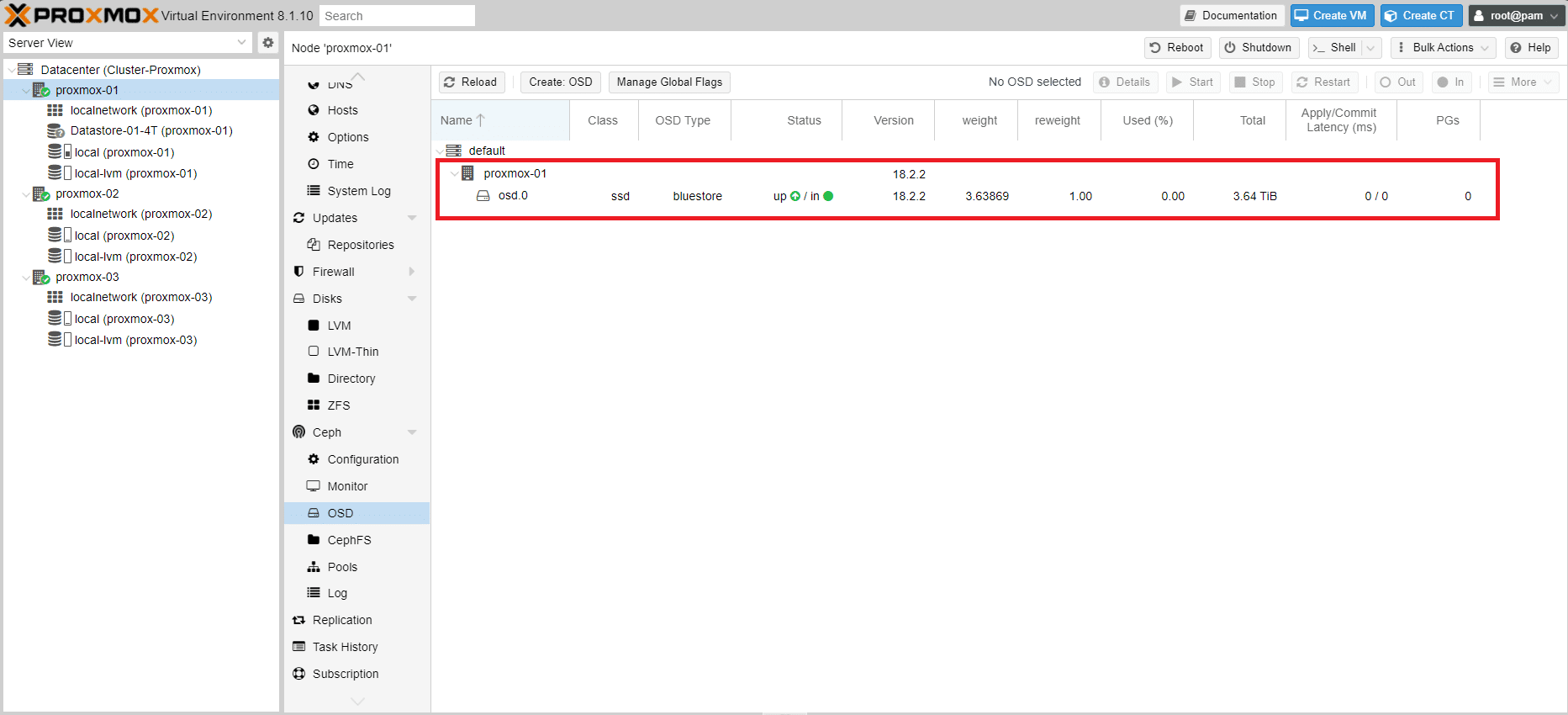
Se è andato tutto a buon fine dovremmo visualizzare l’OSD appena creato in stato UP
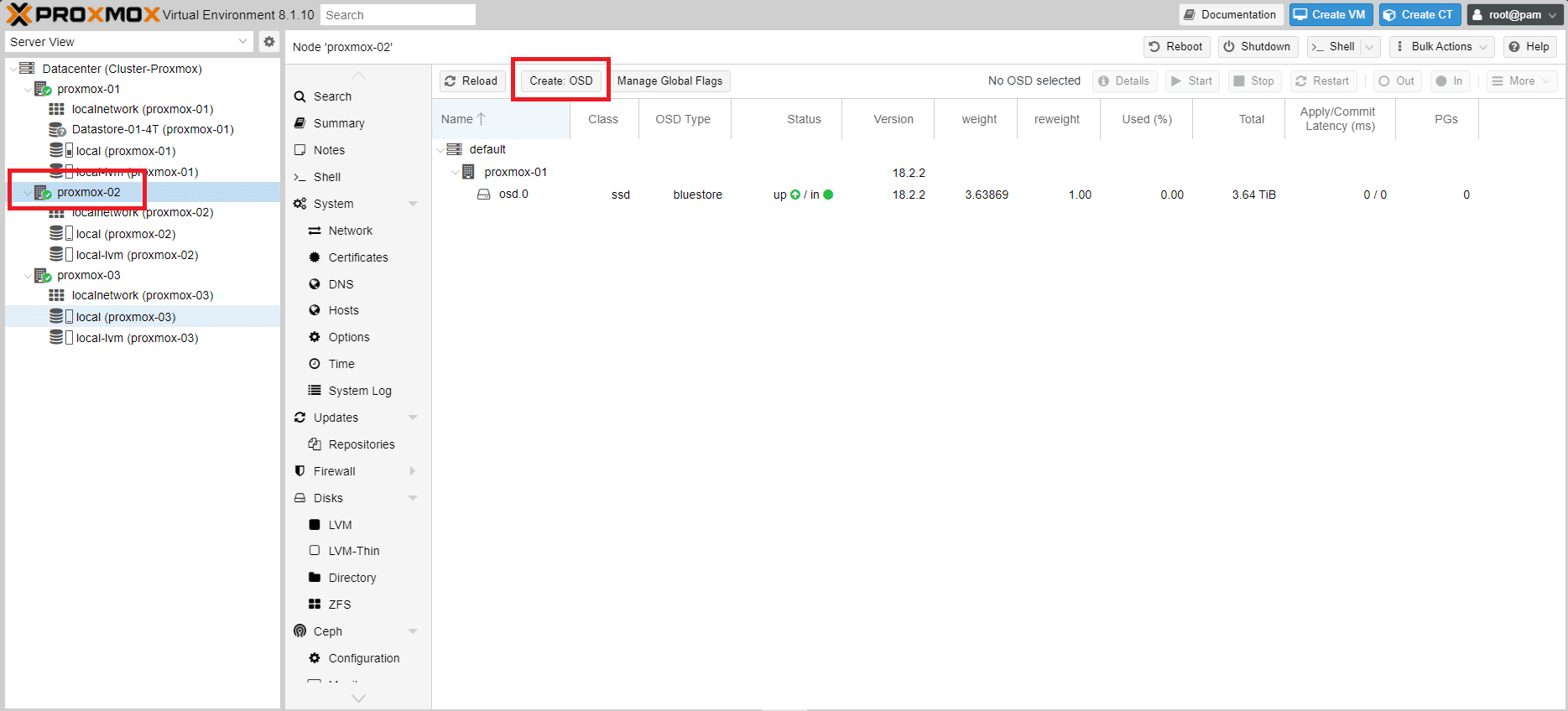
Selezionare il nodo proxmox-02 quindi cliccare sotto il menù Ceph la voce OSD. Cliccare quindi Create: OSD
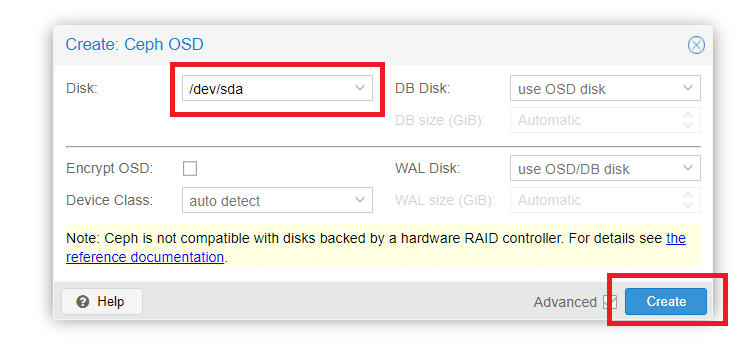
Selezionare il disco (nel mio caso l’unico disco presente è /dev/sda) quindi cliccare su Create
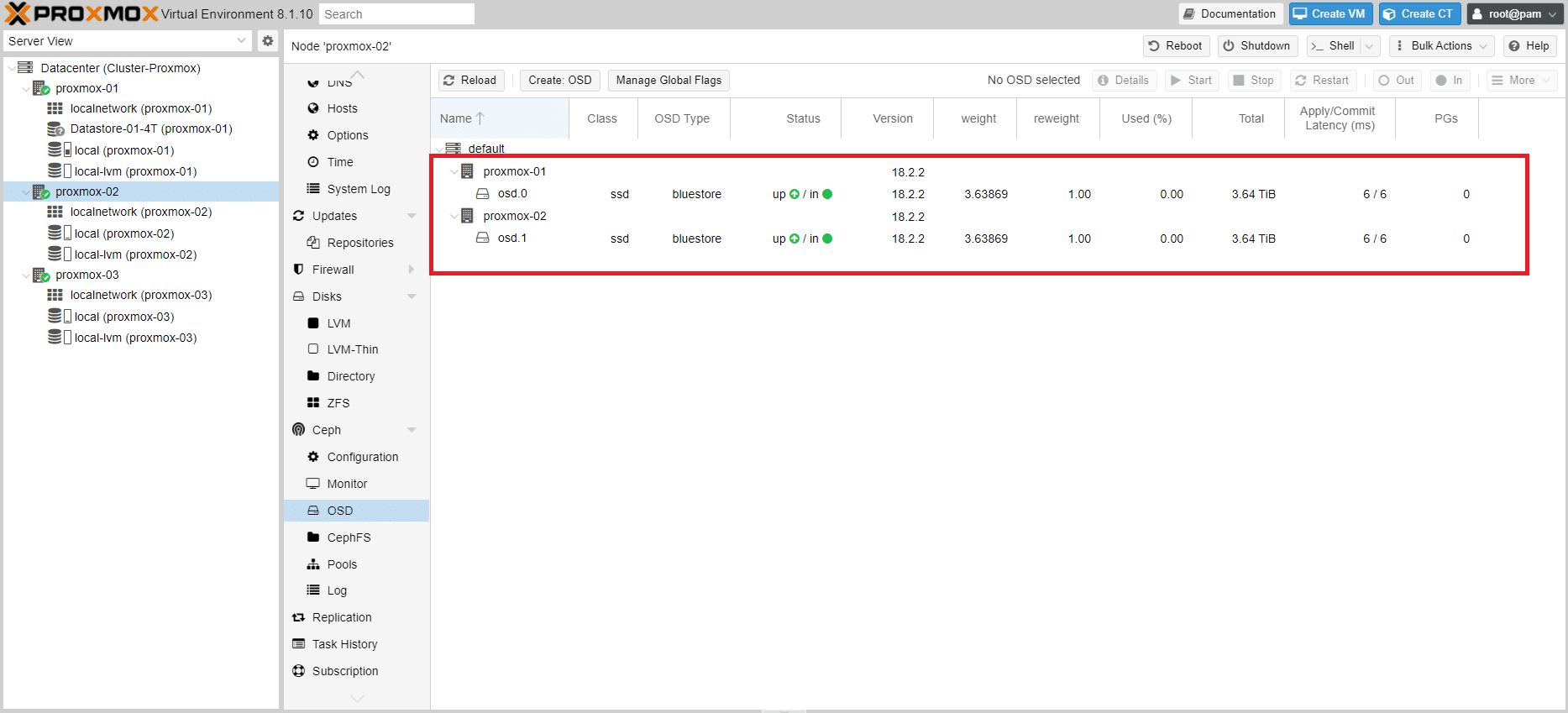
Se è andato tutto a buon fine dovremmo visualizzare l’OSD del proxmox-02 appena creato in stato UP
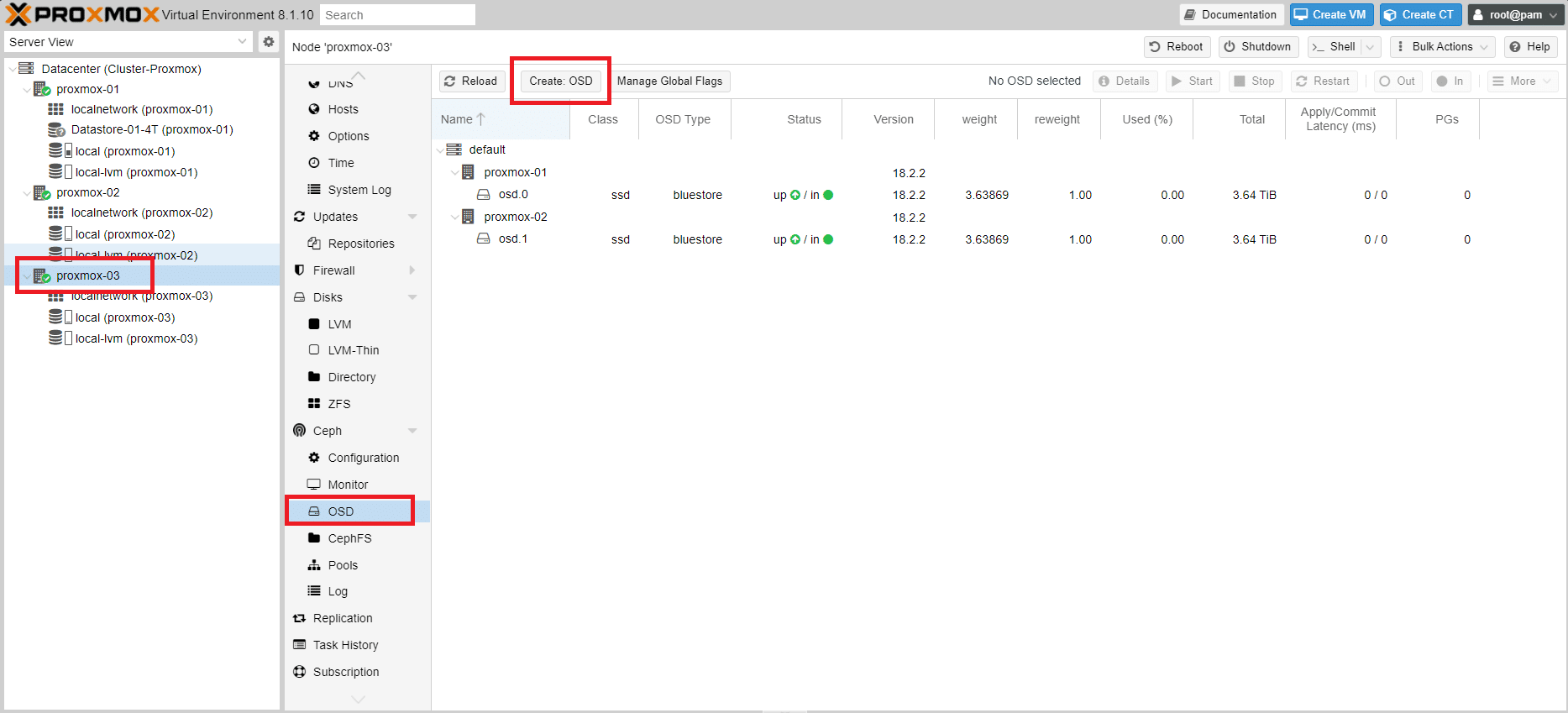
Selezionare il nodo proxmox-03 quindi cliccare sotto il menù Ceph la voce OSD. Cliccare quindi Create: OSD
Selezionare il disco (nel mio caso l’unico disco presente è /dev/sda) quindi cliccare su Create
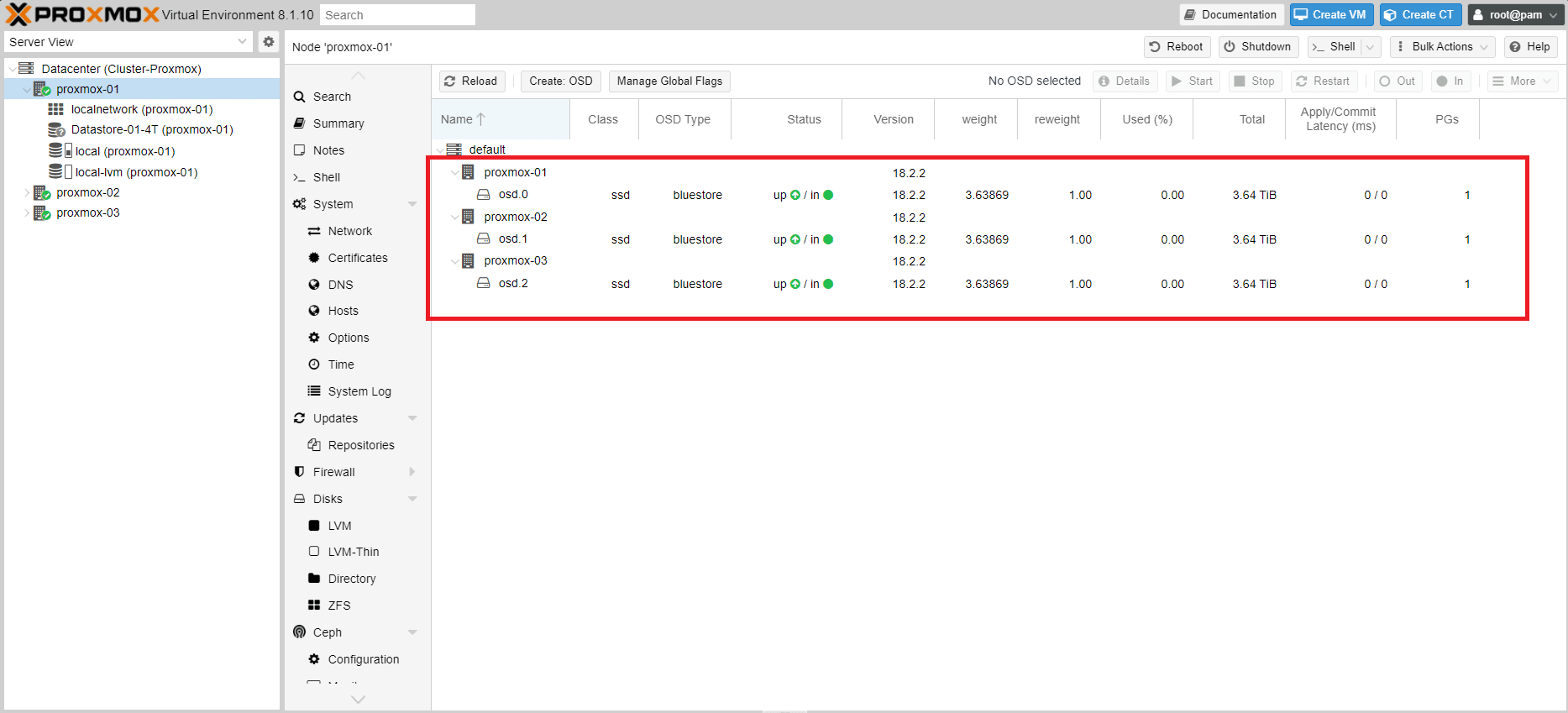
Se è andato tutto a buon fine dovremmo visualizzare i tre OSD creati come mostrato nella figura sovrastante
CONFIGURAZIONE DEI CEPH MONITOR
Aggiungiamo altri Ceph Monitor, poiché abbiamo configurato solo il primo nodo come Ceph Monitor.
Un Ceph Monitor, spesso abbreviato in Ceph Mon, è un componente essenziale in un cluster di storage Ceph. La sua funzione principale è quella di mantenere e gestire la mappa del cluster, una struttura di dati cruciale che tiene traccia dello stato dell’intero cluster, inclusa la posizione dei dati, la topologia del cluster e lo stato di altri demoni nel sistema.
I monitor Ceph contribuiscono in modo significativo alla tolleranza ai guasti e all’affidabilità del cluster. Lavorano in un quorum, il che significa che ci sono più monitoraggi e la maggioranza deve essere d’accordo sullo stato del cluster. Questa configurazione impedisce qualsiasi singolo punto di errore, poiché anche se un monitor diventa inattivo, il cluster può continuare a funzionare con i monitor rimanenti.
Tenendo traccia delle posizioni dei dati e degli stati dei daemon, Ceph Monitor facilita l’accesso efficiente ai dati e contribuisce a garantire il funzionamento senza interruzioni del cluster. Sono inoltre coinvolti nel mantenimento della coerenza dei dati nel cluster e nella gestione dell’autenticazione e dell’autorizzazione dei client.
Di seguito la procedura per aggiungere il secondo e il terzo nodo Proxmox come monitor
Selezionare un nodo qualsiasi
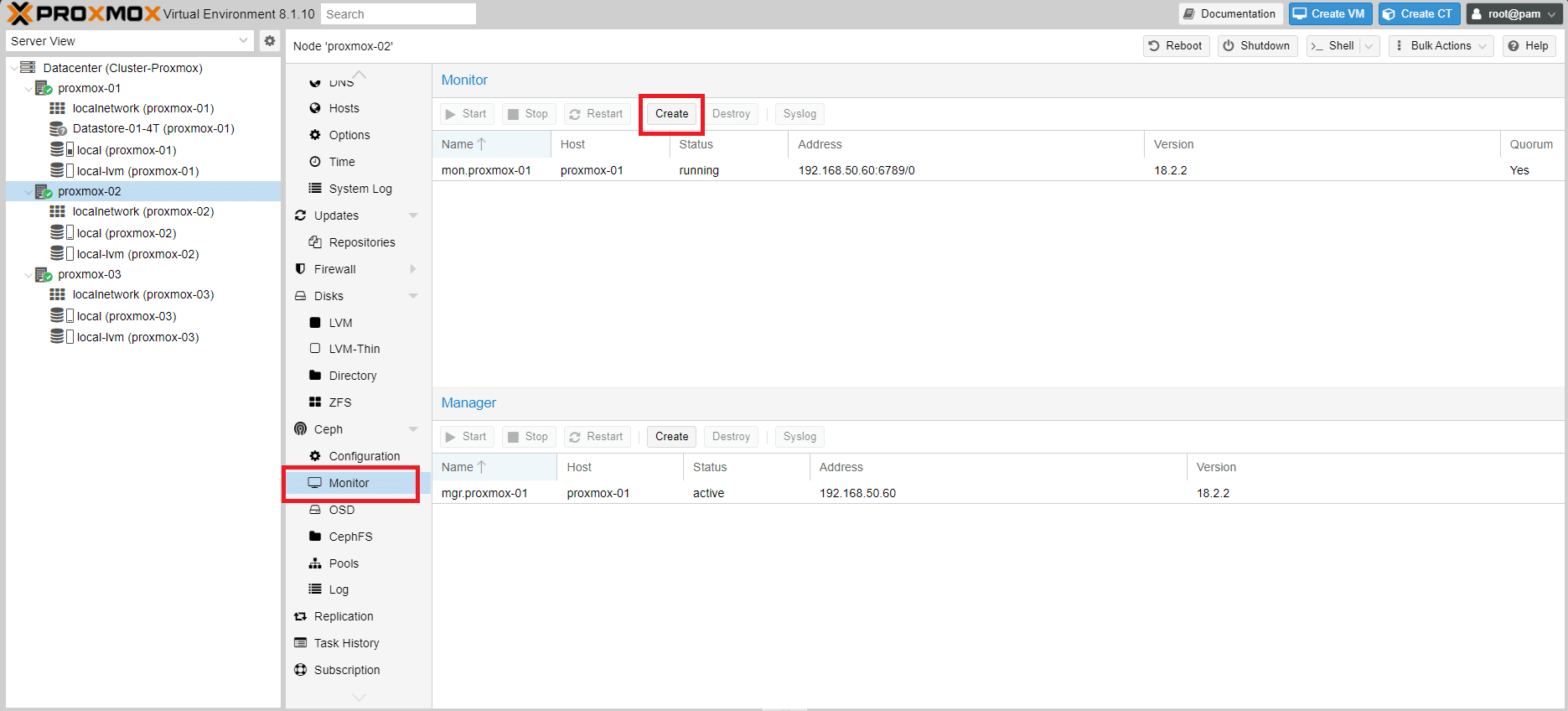
Cliccare su Monitor quindi Create
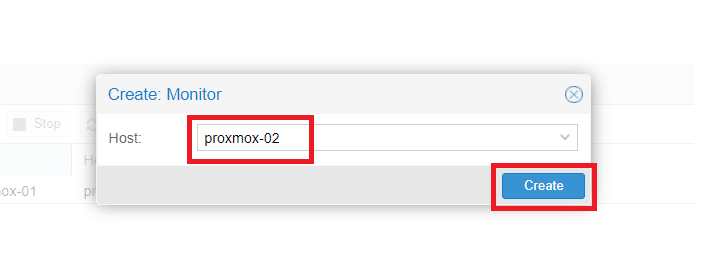
Selezionare l’host proxmox-02 quindi Create
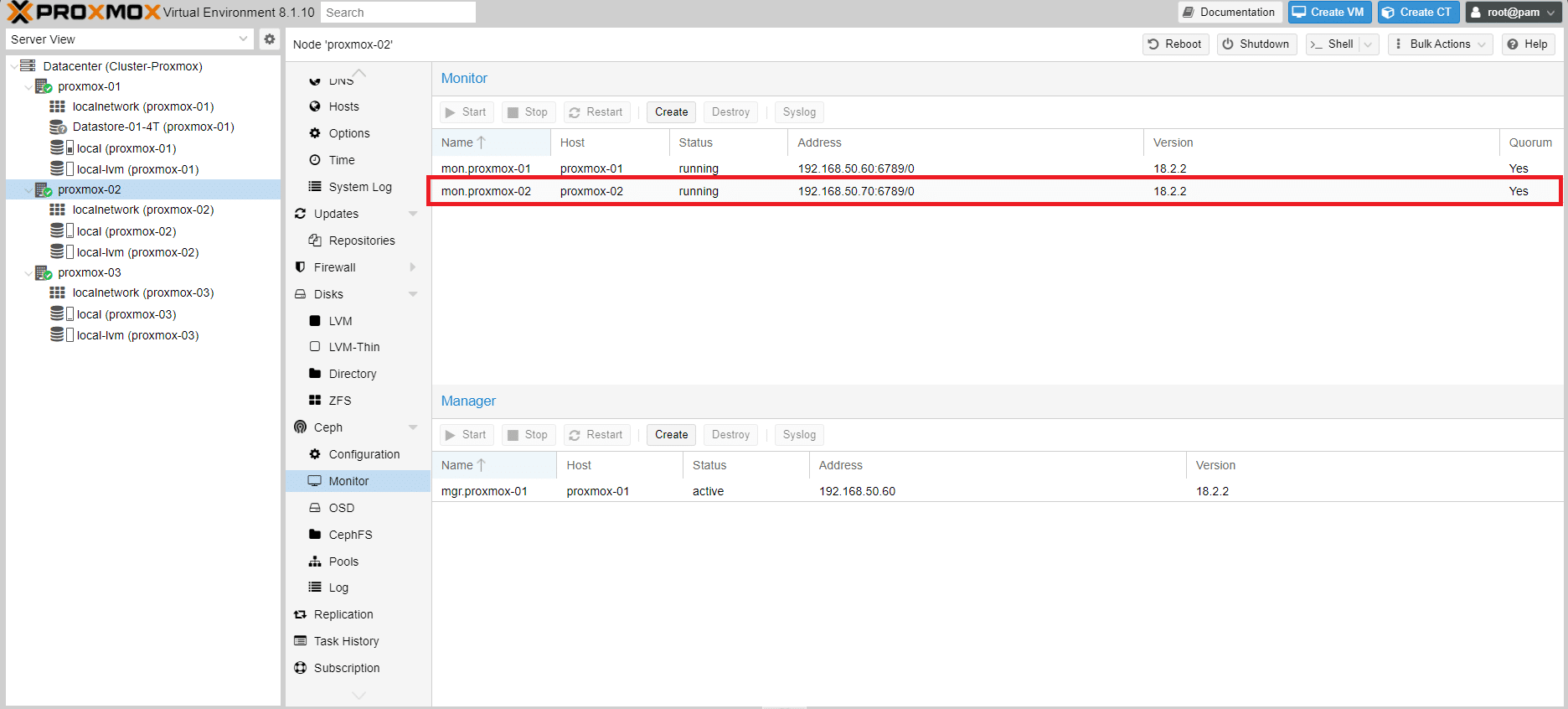
Se è andato tutto a buon fine dovremmo vedere il Monitor relativo al proxmox-02 in running come mostrato nell’immagine sovrastante
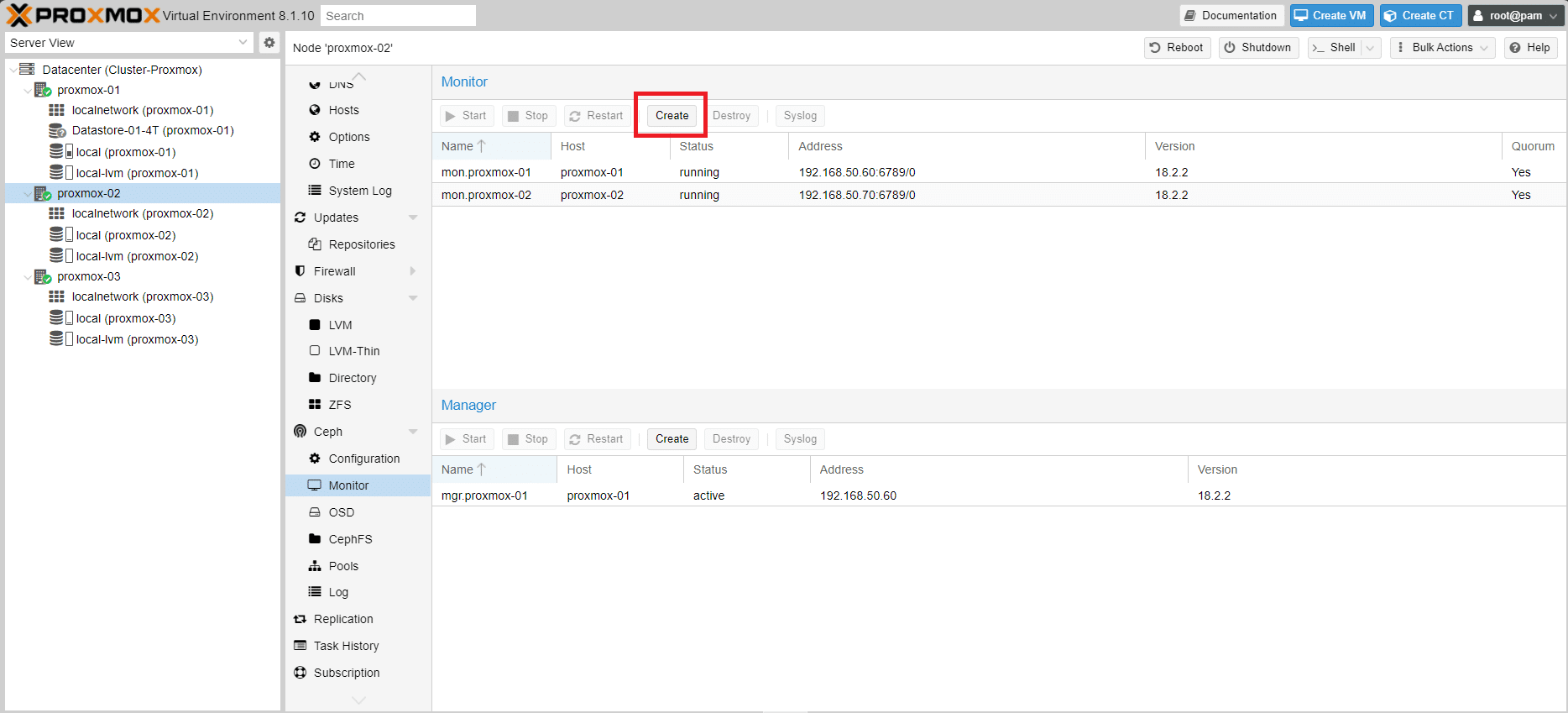
Cliccare Create per procedere con la creazione del Monitor per il terzo Host
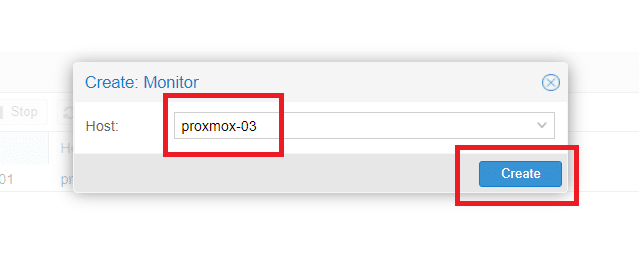
Selezionare il nodo proxmox-03 quindi cliccare Create
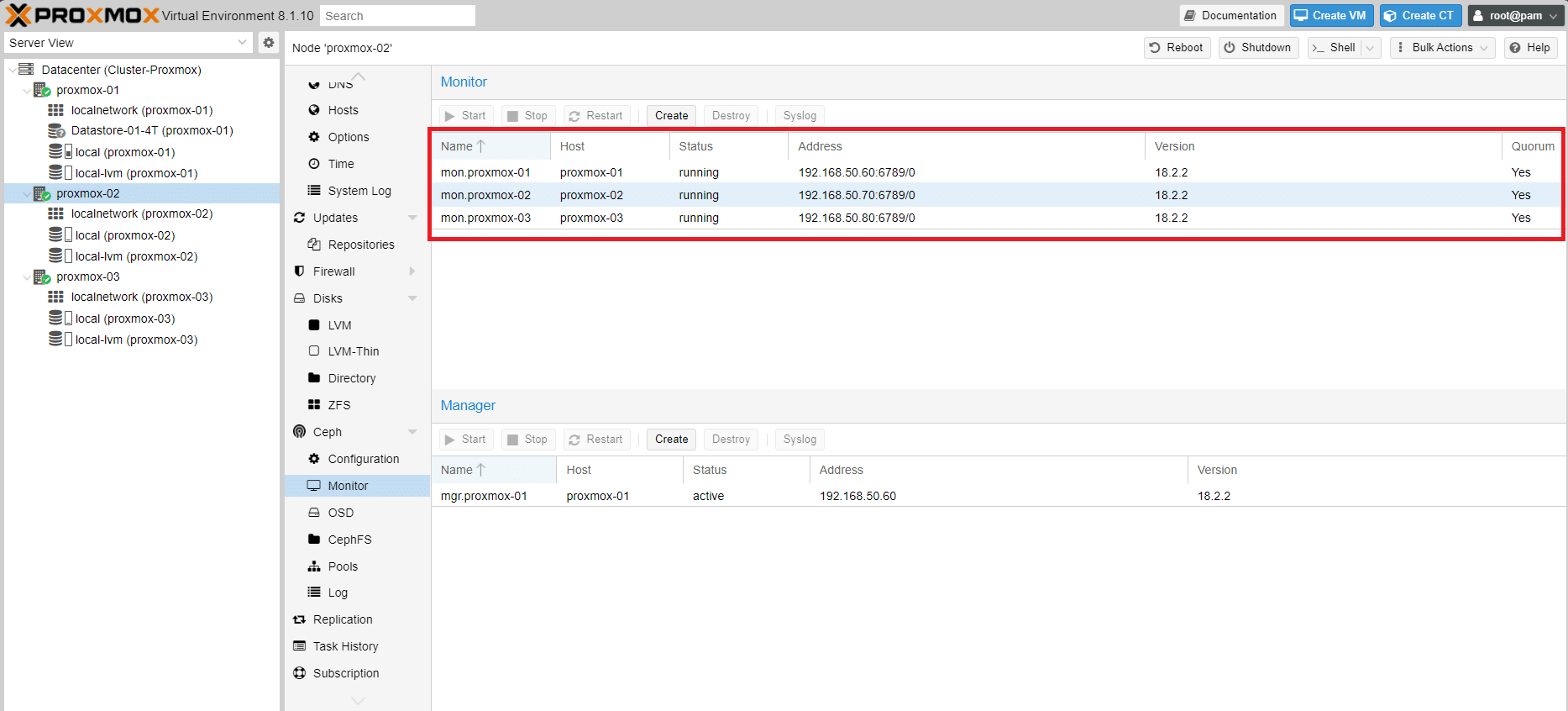
Se è andato tutto a buon fine dovremmo vedere il Monitor di tutti e tre i server proxmox in running come mostrato nell’immagine sovrastante
CONFIGURAZIONE DEI CEPH MANAGER
I Ceph Manager forniscono il cruscotto, raccolgono e distribuiscono i dati statistici ed eseguono attività di ribilanciamento.
Sono necessari per un buon funzionamento del sistema Ceph, ma non sono essenziali.
Quindi, se tutti i manager dovessero cadere non ci sarebbero problemi immediati è sufficiente avviare un altro gestore su un nodo ancora attivo.
Per attivare il Manager selezionare un nodo qualsiasi
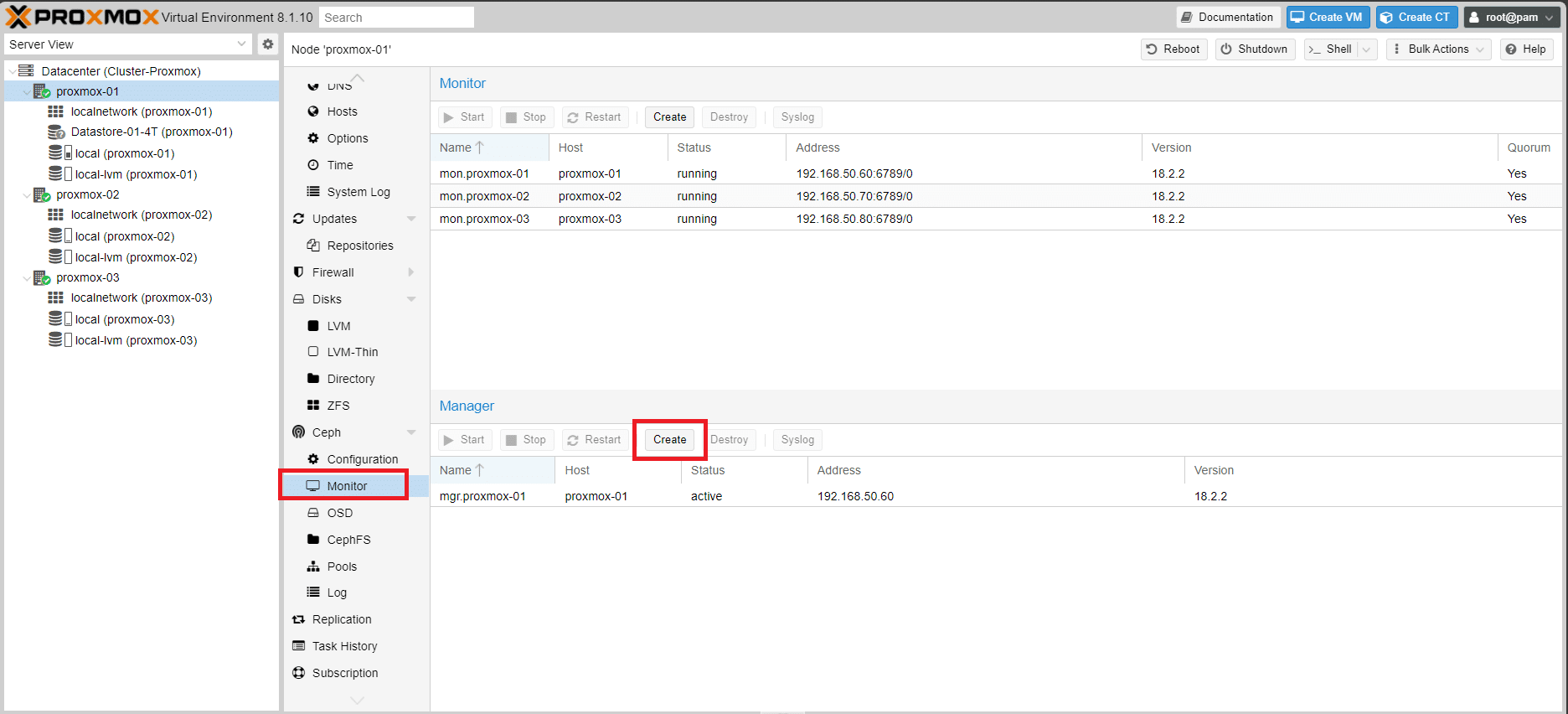
Cliccare su Monitor quindi in corrispondenza della sezione Manager cliccare Create
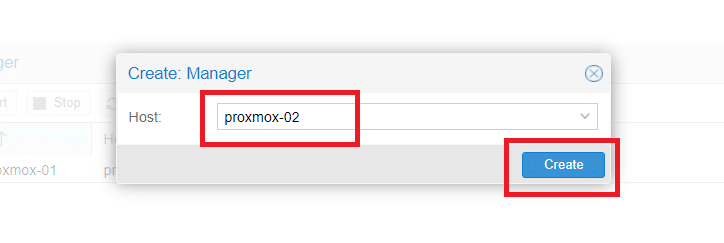
Selezionare il nodo proxmox-02 quindi Create
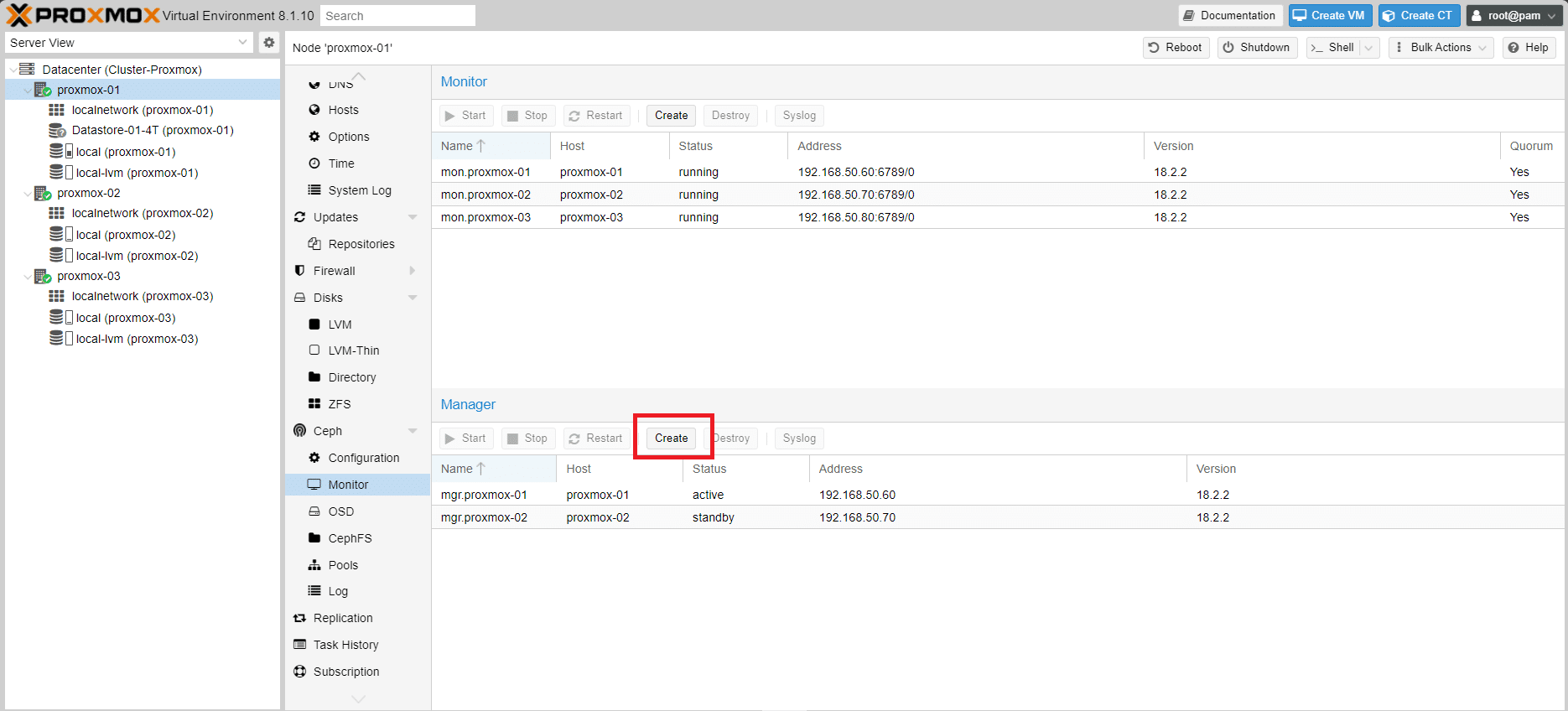
Cliccare nuovamente su Create per aggiungere il terzo nodo
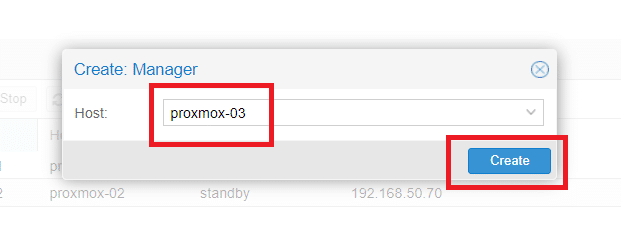
Selezionare il nodo proxmox-03 quindi Create
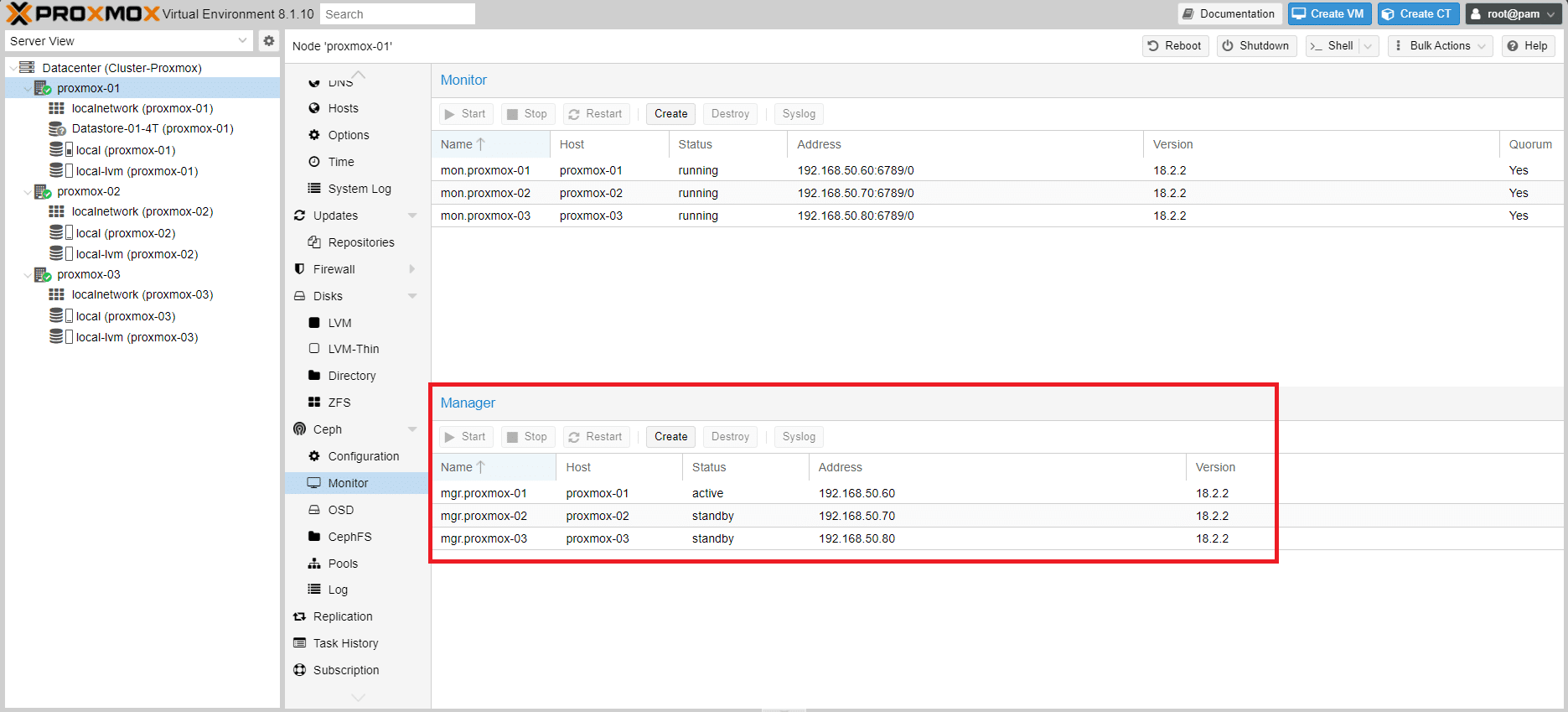
Se è tutto OK dovremmo vedere i tre Manager come mostrato nell’immagine sovrastante.
Il Manager del proxmox-01 sarà attivo e invece gli altri saranno in standby
I demoni del server metadati (MDS) operano in due stati:
Attivo: consente di gestire i metadati per gli archivi di file e directory nel file system Ceph.
Standby: funge da backup e diventa attivo quando un daemon MDS attivo non risponde.
Di default, un file system Ceph utilizza un solo daemon MDS attivo. Tuttavia, i sistemi con molti client traggono vantaggio da più daemon MDS attivi.
È possibile configurare il file system per l’utilizzo di più daemon MDS attivi in modo da poter ridimensionare le prestazioni dei metadati per carichi di lavoro di dimensioni maggiori. I daemon MDS attivi condividono dinamicamente il carico di lavoro dei metadati quando i modelli di caricamento dei metadati cambiano. Si noti che i sistemi con più daemon MDS attivi richiedono ancora che i daemon MDS in standby rimangano a disponibilità elevata.
CREAZIONE DEL CEPH POOL
Quando si crea un Pool dall’interfaccia di Proxmox, di default si può solamente utilizzare la regola CRUSH chiamata replicated_rule.
Se invece si vogliono creare dei Pool differenziandoli per tipo di dischi bisogna eseguire i seguenti comandi da Shell:
|
0
1
2
|
ceph osd crush rule create-replicated Gruppo_HDD default host hdd
ceph osd crush rule create-replicated Gruppo_SSD default host hdd
|
NOTA BENE: Questa è un operazione che non si può gestire dalla GUI di Proxmox, ma lo si può fare lanciando questi due comandi su uno dei tre host del cluster (è indifferente su quale nodo si eseguono)
In questo tutorial utilizzeremo il Pool di default presente in Proxmox
Per accedere al menù di creazione del pool cliccare su uno dei nodi
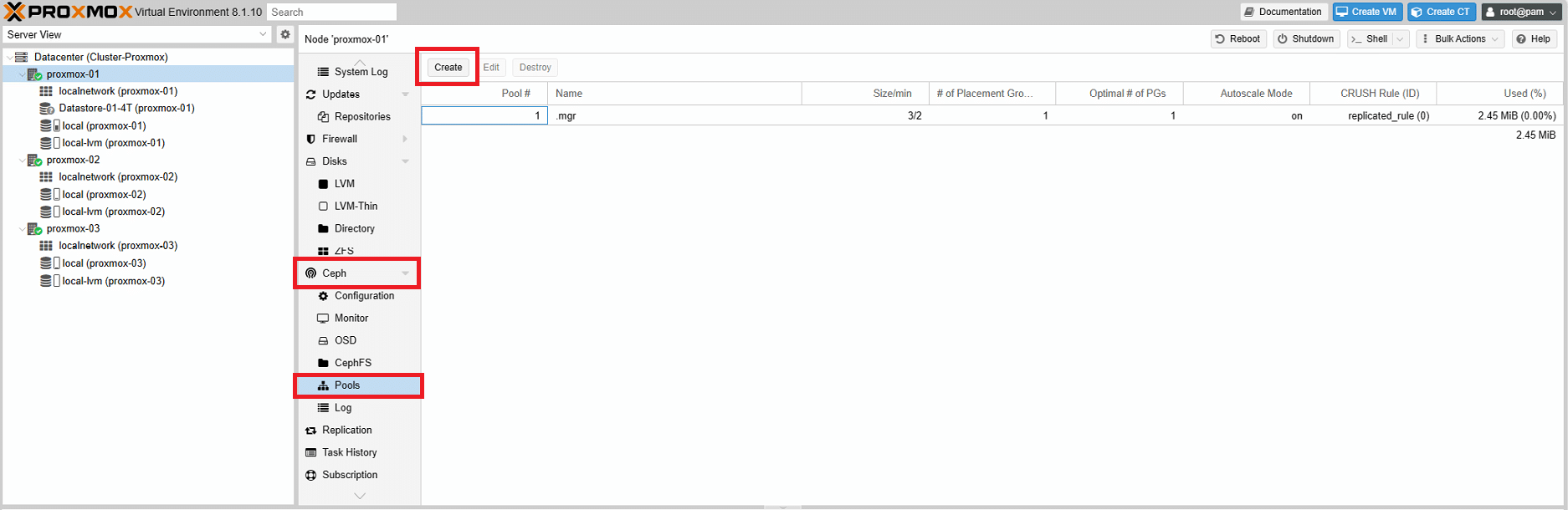
Quindi selezionare Ceph > Pools e cliccare su Create
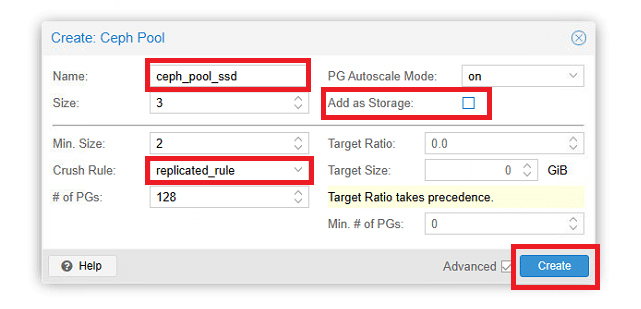
Dare un nome al Pool (ceph_pool_ssd) quindi selezionare la regola di Crush. Cliccare Create
ATTENZIONE: Ricordarsi di non selezionare Add as Storage, in quanto lo storage di Proxmox dedicato a Ceph lo andremo ad inserire manualmente.
Di default, un pool viene creato con 128 PG (Placement Group). Questo è un numero che può variare ma dipende da alcuni fattori che vedremo nel prossimo paragrafo.
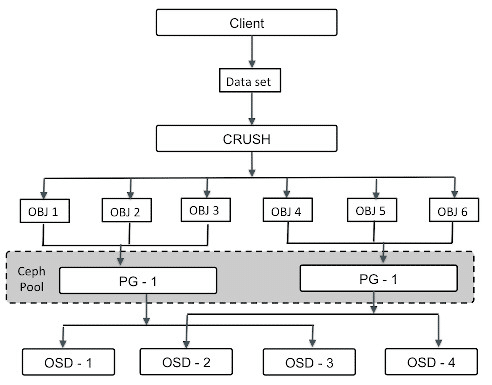
Come evidenziato nella figura sovrastante, Il Pool è di fatto un raggruppamento logico dei PG. Infatti i PG vengono fisicamente distribuiti tra i dischi gestiti dagli OSD.
Ricordare che esiste un solo OSD per ogni disco dedicato a Ceph
Selezionando il campo Size = 3 si sta specificando che ogni PG dovranno essere replicati 3 volte nel cluster.
Questo è un valore da tenere in considerazione quando dobbiamo stimare la dimensione dei dischi durante il dimensionamento del cluster.
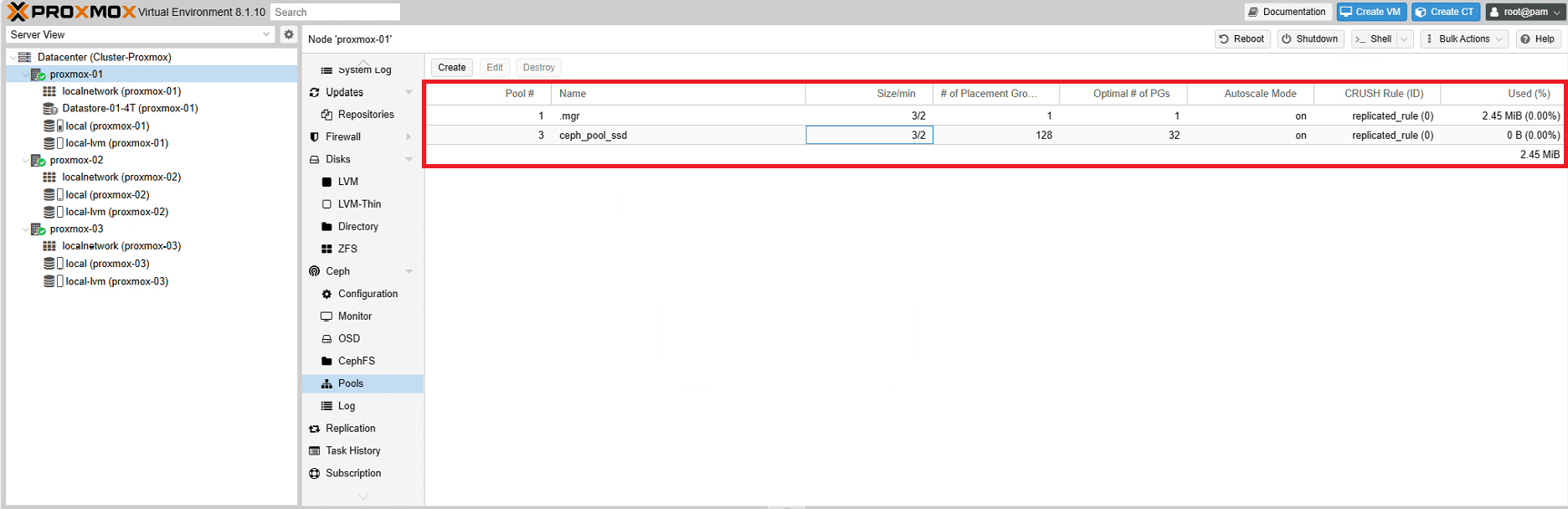
Una volta creato il pool Ceph dovremmo visualizzare una schermata come quella sovrastante
CREAZIONE DEGLI STORAGE PER IL CLUSTER PROXMOX
Ora siamo pronti per creare i due storage che ospiteranno le nostre macchine virtuali.
Andiamo su Datacenter quindi selezionare Storage
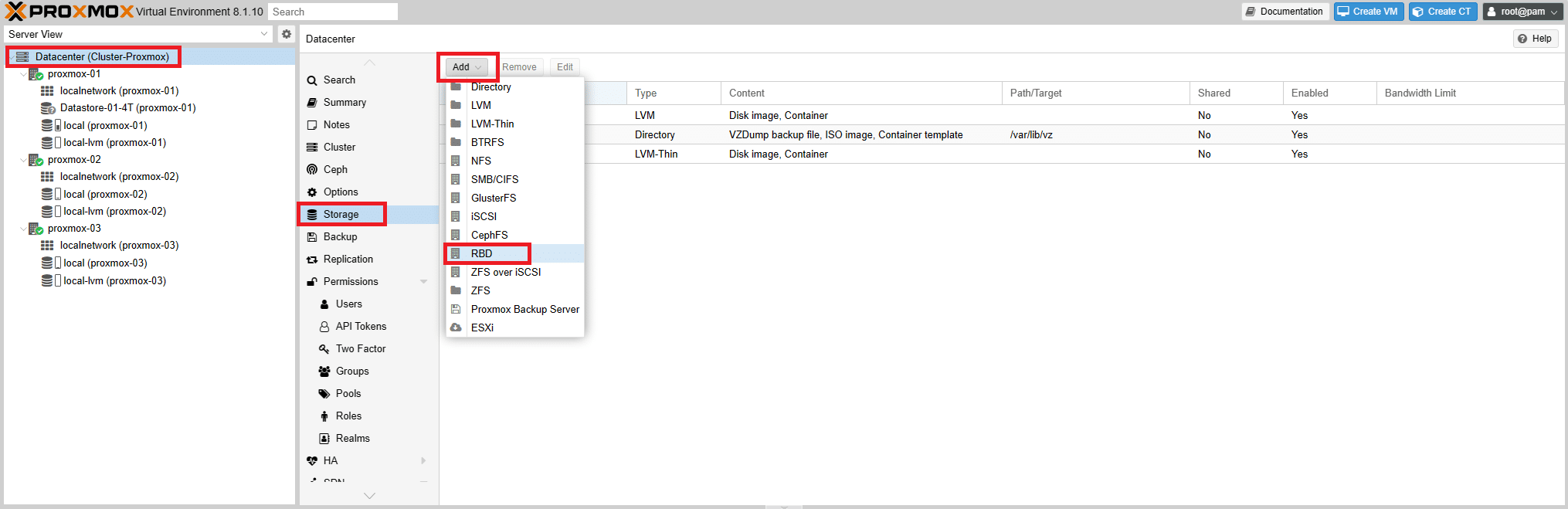
Cliccare su Add quindi selezionare RBD, ovvero lo Storage a Blocchi che utilizza Ceph come mostrato nell’immagine sovrastante
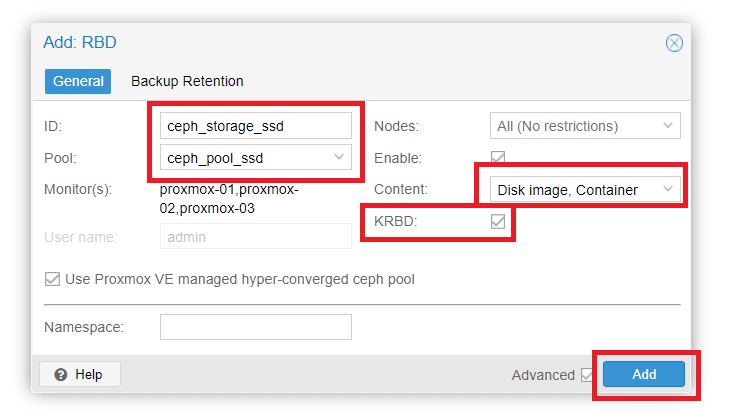
Come da figura sovrastante inserire il nome ID ceph_storage_ssd e selezionare il Pool ceph_pool_ssd creato precedentemente.
ATTENZIONE: Selezionare l’opzione KRBD per poter impostare come Content sia Disk Image che Container
Cliccare Add per aggiungere lo storage ceph_storage_ssd
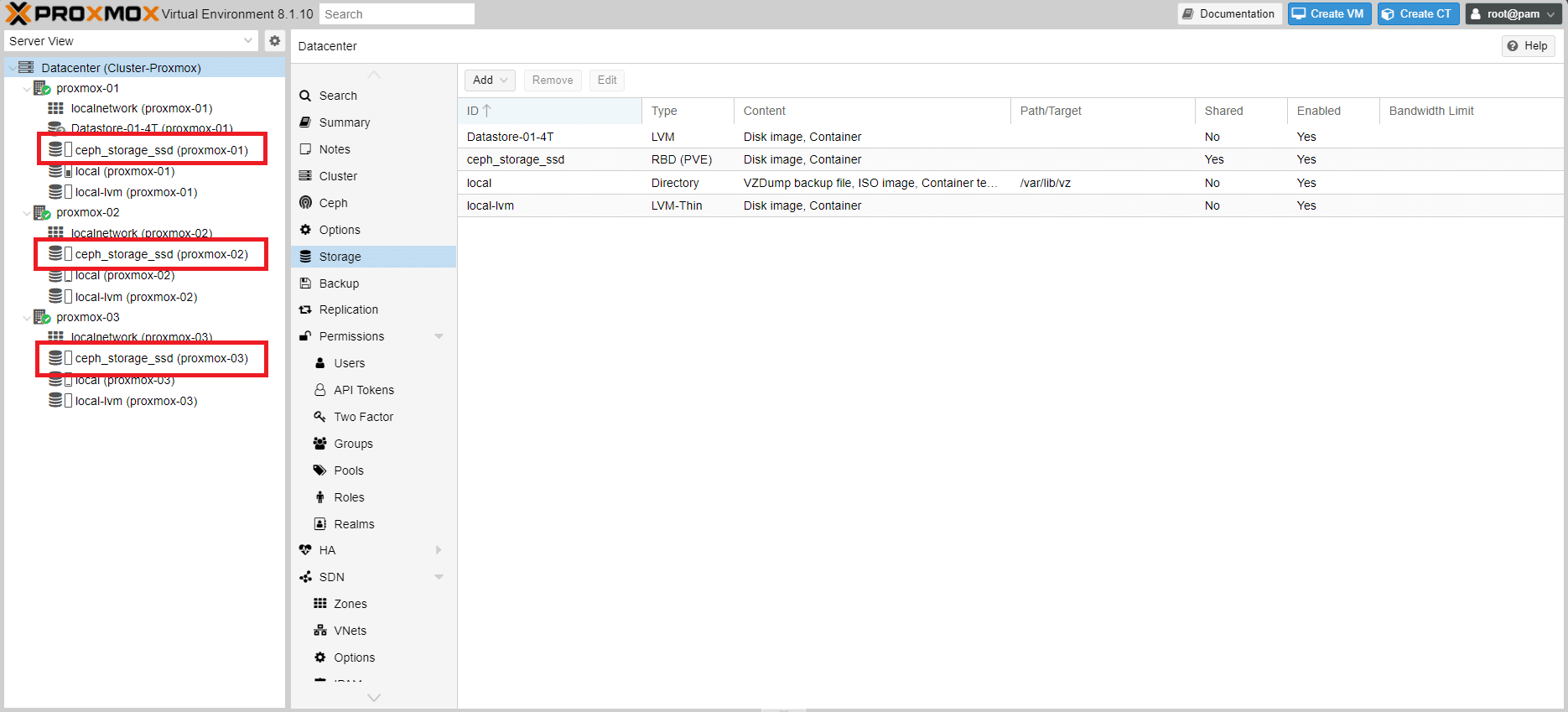
Se abbiamo fatto tutto correttamente dovremmo vedere lo storage ceph_storage_ssd mappato su tutti e tre i nodo Proxmox.
Ora bisogna calcolare quanto spazio si ha a disposizione per lo storage.
3 dischi SSD da 4TB che ridimensionati da Proxmox sono 3,64 TB = 10.92 TB circa
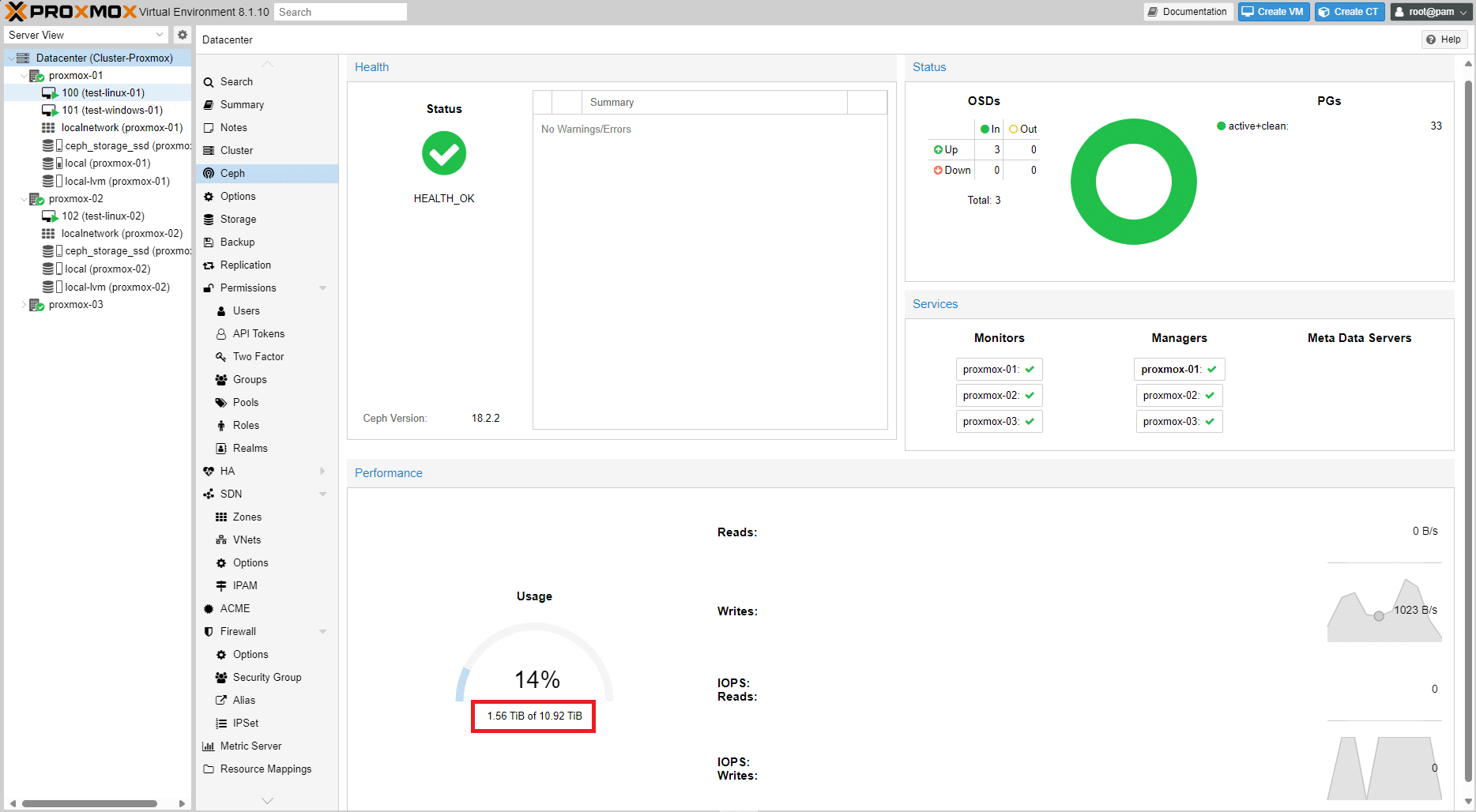
Dall’immagine sovrastante è possibile vedere lo spazio disponibile in Ceph
Considerando che bisogna garantire 2 repliche (campo Size impostato) si avrà:
ceph_storage_ssd = 10.92 TB / 2 = 5,46 TB circa
CALCOLO DEL NUMERO DI PLACEMENT GROUP (PG)
Il numero di PG per ogni Pool è stimabile in base alla formula che mette a disposizione Ceph sul sito ufficiale
Il calcolatore di Ceph è presente al seguente link
https://docs.ceph.com/en/latest/rados/operations/pgcalc/
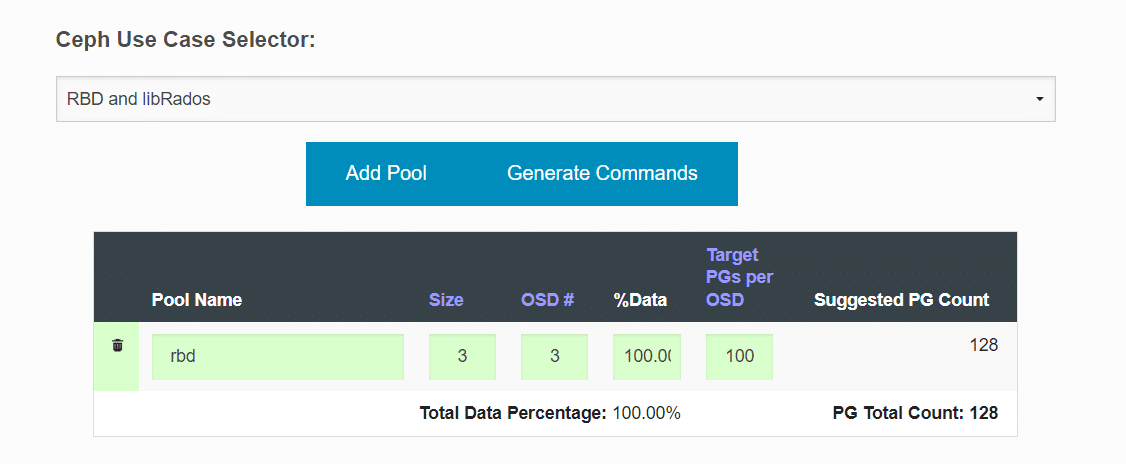
Pool Name: Nome dei pool in questione. I nomi tipici dei pool sono i seguenti:

Size: Numero di repliche di cui avrà il pool. Il valore predefinito 3 è precompilato.
OSD#: Numero di OSD in cui questo pool avrà i PG. In genere, si tratta dell’intero conteggio OSD del cluster, ma potrebbe essere inferiore in base alle regole CRUSH. (ad esempio set di dischi SSD e SATA separati)
%Data: Questo valore rappresenta la percentuale approssimativa di dati che saranno contenuti in questo pool per quello specifico set OSD. Gli esempi sono precompilati di seguito come guida.
Target PGs per OSD: Questo valore deve essere popolato in base alle seguenti indicazioni:
100 – Se non si prevede che il conteggio OSD del cluster aumenti nel prossimo futuro.
200 – Se si prevede che il numero di OSD dei cluster aumenterà (fino a raddoppiare le dimensioni) nel prossimo futuro.
CONFIGURAZIONE HA
Nella sezione Datacenter passare selezionare HA
Quindi selezionare Groups
Cliccare su Create
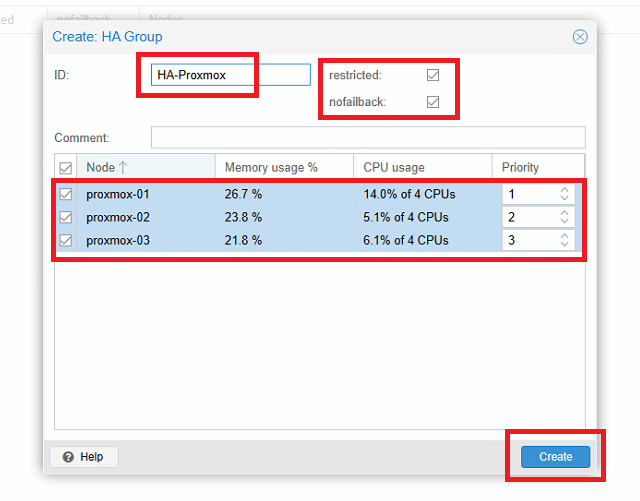
Assegnare un nome al gruppo (HA-proxmox) quindi selezionare i tre nodi Proxmox e impostare una priorità.
Impostare i seguenti parametri a piacimento:
Restricted: Limita l’esecuzione delle risorse solo sui nodi appartenenti a questo gruppo HA.
Nofailback: Se si verifica un errore in un nodo che attualmente esegue le risorse, HA eseguirà la migrazione di tali risorse ad altri nodi integri. Scegliere se eseguire la migrazione delle risorse al nodo originale dopo il ripristino. In genere si consiglia di abilitare questa opzione per evitare di attivare migrazioni di risorse eccessive, che potrebbero causare una pressione eccessiva della larghezza di banda di rete e dell’I/O del disco.
Comment: Aggiungi eventuali osservazioni o informazioni aggiuntive.
Node List: Specificare quali nodi PVE devono essere inclusi in questo gruppo HA. Per ogni nodo è possibile assegnare un livello di priorità. I livelli di priorità più alti indicano una preferenza per l’esecuzione delle risorse in tale nodo. Considerare le caratteristiche delle prestazioni di ogni nodo quando si determina la priorità.
Cliccare Create per procedere con la creazione del gruppo
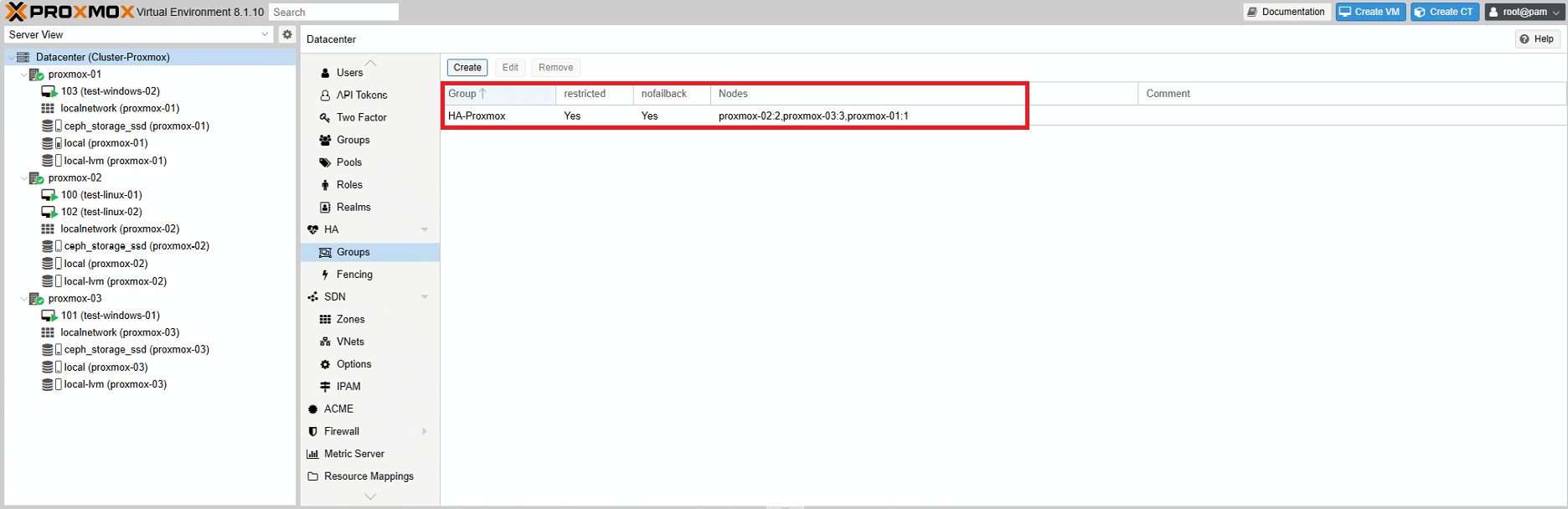
Una volta completata la configurazione, è possibile visualizzare il gruppo HA creato come mostrato nell’immagine sovrastante
A questo punto aggiungere le risorse alla configurazione a disponibilità elevata
Cliccare su Datacenter quindi HA
Nella sezione Resources cliccare Add
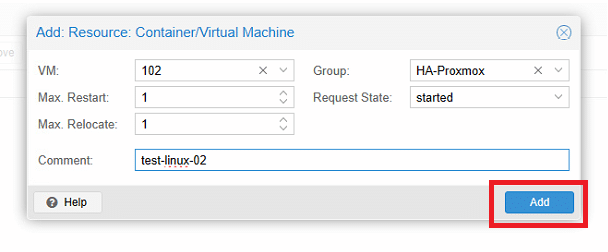
In questa interfaccia di aggiunta delle risorse configurare i seguenti parametri:
VM: Selezionare la risorsa CT o VM desiderata dall’elenco a discesa.
Max Restart: Specificare il numero massimo di tentativi di riavvio in caso di errore di avvio della risorsa.
Max Relocate: Specificare il numero massimo di rilocazioni al nodo successivo dopo aver raggiunto il limite massimo di riavvio.
Group: Scegliere il gruppo a disponibilità elevata in cui deve essere eseguita la risorsa dall’elenco a discesa.
Request State: Selezionare lo stato di esecuzione desiderato per la risorsa, che può essere uno dei seguenti:
– Started: la disponibilità elevata garantisce che la risorsa rimanga nello stato avviato.
– Stopped: la disponibilità elevata garantisce che la risorsa rimanga nello stato arrestato.
– Ignored: la disponibilità elevata ignora questa risorsa e non esegue alcuna azione su di essa.
– Disabled: la disponibilità elevata garantisce che la risorsa rimanga nello stato arrestato e non tenti la migrazione ad altri nodi.
– Comment: Osservazioni o note aggiuntive per la risorsa.
Cliccare Add per aggiungere la risorsa
NOTA BENE: ripetere la procedura di aggiunta risorse per ogni VM o Container che si intende mettere in alta affidabilità.
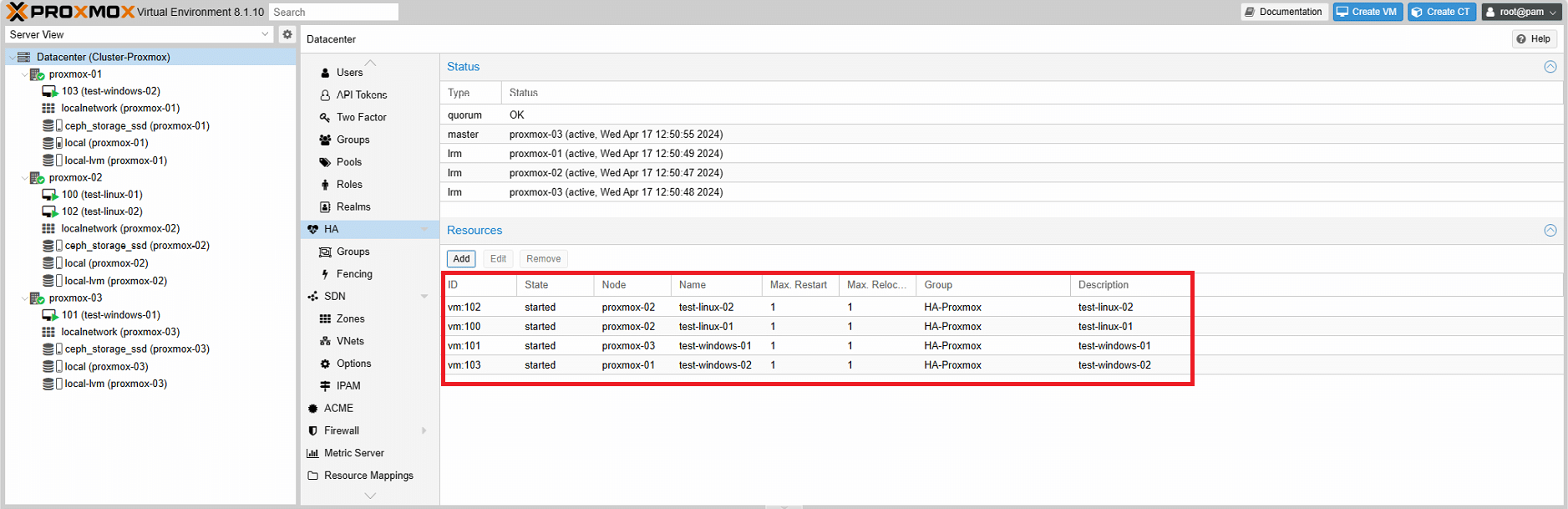
Dopo aver aggiunto le risorsa, si noterà un cambiamento nello stato HA, che indica che la risorsa è stata aggiunta come mostrato nell’imamgine sovrastante
Per verificare il funzionamento della funzionalità HA, è possibile simulare un errore del nodo.
Arrestare il nodo che esegue la macchina virtuale e si osserverà il meccanismo di watchdog che attiva un riavvio.
Dopo una breve attesa si vedrà che la macchina virtuale migrerà in un altro nodo e verrà eseguita li.
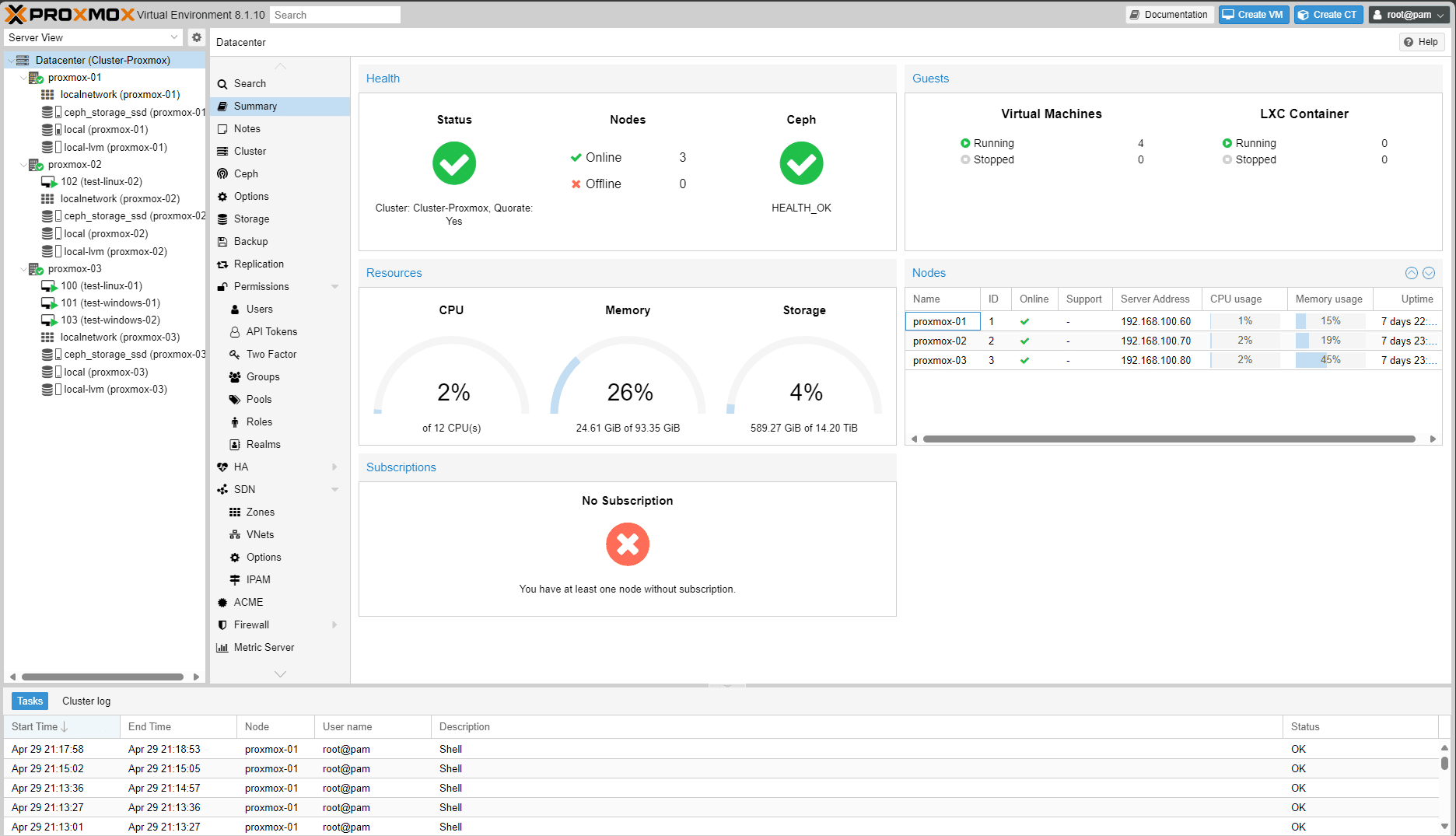
Sopra una schermata che mostra la Dashboard Summary del Cluster Proxmox
TIPS AND TRICKS CEPH
L’installazione di Ceph potrebbe presentare i seguenti errori.
Multiple IPs for ceph public network detected on proxmox use ‘mon-address’ to specify one of them. (500)
oppure
Ceph offline, web interface says 500 timeout
In questi casi eseguire il comando:
|
0 |
pveceph mon create --mon-address 192.168.50.60
|
Sotto i due path di configurazione del file Ceph (modificando il file /etc/pve/ceph.conf si dovrebbe modificare anche il file /etc/ceph/ceph.conf)
|
0
1
2
|
nano /etc/pve/ceph.conf
nano /etc/ceph/ceph.conf
|
Una configurazione corretta dovrebbe presentare il seguente output:
|
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
[global]
auth_client_required = cephx
auth_cluster_required = cephx
auth_service_required = cephx
cluster_network = 192.168.50.0/24
fsid = 6d035f35-f61d-4b1c-932d-ab6280a47c1b
mon_allow_pool_delete = true
mon_host = 192.168.50.60 192.168.50.70 192.168.50.80
ms_bind_ipv4 = true
ms_bind_ipv6 = false
osd_pool_default_min_size = 2
osd_pool_default_size = 3
public_network = 192.168.50.0/24
[client]
keyring = /etc/pve/priv/$cluster.$name.keyring
[mon.proxmox-01]
public_addr = 192.168.50.60
[mon.proxmox-02]
public_addr = 192.168.50.70
[mon.proxmox-03]
public_addr = 192.168.50.80
|


































0 commenti