


Nel calcolo, una tabella codici è una tabella di valori che descrive il set di caratteri utilizzato per codificare un particolare set di caratteri, solitamente combinato con un numero di caratteri di controllo.
Il termine “code page” deriva dai sistemi mainframe basati su EBCDIC di IBM, da Microsoft, SAP e Oracle Corporation sono tra i pochi fornitori che utilizzano questo termine.
La maggior parte dei venditori identifica i propri set di caratteri con un nome. Nel caso in cui ci sia una pletora di set di caratteri (come in IBM), identificare i set di caratteri attraverso un numero è un modo conveniente per distinguerli. Originariamente, i numeri delle code page si riferivano ai numeri di pagina nel manuale del set di caratteri standard IBM, una condizione che non è stata mantenuta per molto tempo.
I fornitori che utilizzano un sistema di code page assegnano il proprio numero di codice pagina a una codifica di caratteri, anche se è meglio conosciuto con un altro nome; ad esempio, all’UTF-8 sono stati assegnati i numeri di pagina 1208 su IBM, 65001 su Microsoft e 4110 su SAP.
Hewlett-Packard utilizza un concetto simile nel suo sistema operativo HP-UX e nel suo protocollo Printer Command Language (PCL) per stampanti (sia per stampanti HP che non).
La terminologia, tuttavia, è diversa: ciò che altri chiamano un set di caratteri, HP chiama un set di simboli e ciò che IBM o Microsoft chiamano una code page, HP chiama un codice di set di simboli. HP ha sviluppato una serie di set di simboli, ciascuno con un codice di simboli associato, per codificare sia i propri set di caratteri che i set di caratteri di altri fornitori.
La moltitudine di set di caratteri consente a molti fornitori di consigliare Unicode.
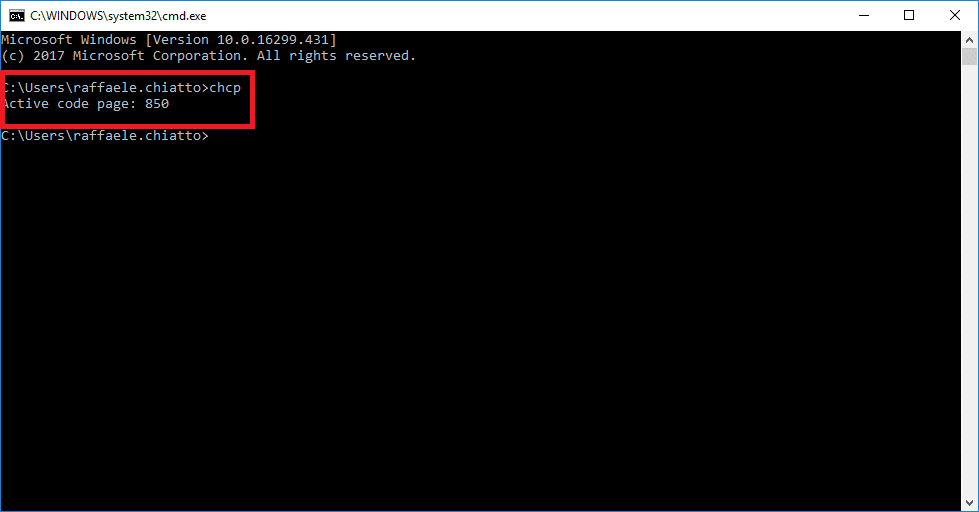
VISUALIZZARE IL CODE PAGE IN WINDOWS
Basta aprire una finestra di DOS e lanciare il comando
|
0 |
chcp |
MODIFICARE IL CODE PAGE IN WINDOWS
Basta aprire una finestra di DOS e lanciare il comando
|
0 |
chcp 65001 |

al posto del code page 65001 potete inserire tutti quelli elencati di seguito:
NOTA BENE: per comodità elencherò solo i code page più comuni dei vendors più conosciuti. Al seguente link ne potete trovare tanti altri https://en.wikipedia.org/wiki/Code_page
| Identifier | .NET Name | Additional information |
| 037 | IBM037 | IBM EBCDIC US-Canada |
| 437 | IBM437 | OEM United States |
| 500 | IBM500 | IBM EBCDIC International |
| 708 | ASMO-708 | Arabic (ASMO 708) |
| 709 | Arabic (ASMO-449+, BCON V4) | |
| 710 | Arabic – Transparent Arabic | |
| 720 | DOS-720 | Arabic (Transparent ASMO); Arabic (DOS) |
| 737 | ibm737 | OEM Greek (formerly 437G); Greek (DOS) |
| 775 | ibm775 | OEM Baltic; Baltic (DOS) |
| 850 | ibm850 | OEM Multilingual Latin 1; Western European (DOS) |
| 852 | ibm852 | OEM Latin 2; Central European (DOS) |
| 855 | IBM855 | OEM Cyrillic (primarily Russian) |
| 857 | ibm857 | OEM Turkish; Turkish (DOS) |
| 858 | IBM00858 | OEM Multilingual Latin 1 + Euro symbol |
| 860 | IBM860 | OEM Portuguese; Portuguese (DOS) |
| 861 | ibm861 | OEM Icelandic; Icelandic (DOS) |
| 862 | DOS-862 | OEM Hebrew; Hebrew (DOS) |
| 863 | IBM863 | OEM French Canadian; French Canadian (DOS) |
| 864 | IBM864 | OEM Arabic; Arabic (864) |
| 865 | IBM865 | OEM Nordic; Nordic (DOS) |
| 866 | cp866 | OEM Russian; Cyrillic (DOS) |
| 869 | ibm869 | OEM Modern Greek; Greek, Modern (DOS) |
| 870 | IBM870 | IBM EBCDIC Multilingual/ROECE (Latin 2); IBM EBCDIC Multilingual Latin 2 |
| 874 | windows-874 | ANSI/OEM Thai (ISO 8859-11); Thai (Windows) |
| 875 | cp875 | IBM EBCDIC Greek Modern |
| 932 | shift_jis | ANSI/OEM Japanese; Japanese (Shift-JIS) |
| 936 | gb2312 | ANSI/OEM Simplified Chinese (PRC, Singapore); Chinese Simplified (GB2312) |
| 949 | ks_c_5601-1987 | ANSI/OEM Korean (Unified Hangul Code) |
| 950 | big5 | ANSI/OEM Traditional Chinese (Taiwan; Hong Kong SAR, PRC); Chinese Traditional (Big5) |
| 1026 | IBM1026 | IBM EBCDIC Turkish (Latin 5) |
| 1047 | IBM01047 | IBM EBCDIC Latin 1/Open System |
| 1140 | IBM01140 | IBM EBCDIC US-Canada (037 + Euro symbol); IBM EBCDIC (US-Canada-Euro) |
| 1141 | IBM01141 | IBM EBCDIC Germany (20273 + Euro symbol); IBM EBCDIC (Germany-Euro) |
| 1142 | IBM01142 | IBM EBCDIC Denmark-Norway (20277 + Euro symbol); IBM EBCDIC (Denmark-Norway-Euro) |
| 1143 | IBM01143 | IBM EBCDIC Finland-Sweden (20278 + Euro symbol); IBM EBCDIC (Finland-Sweden-Euro) |
| 1144 | IBM01144 | IBM EBCDIC Italy (20280 + Euro symbol); IBM EBCDIC (Italy-Euro) |
| 1145 | IBM01145 | IBM EBCDIC Latin America-Spain (20284 + Euro symbol); IBM EBCDIC (Spain-Euro) |
| 1146 | IBM01146 | IBM EBCDIC United Kingdom (20285 + Euro symbol); IBM EBCDIC (UK-Euro) |
| 1147 | IBM01147 | IBM EBCDIC France (20297 + Euro symbol); IBM EBCDIC (France-Euro) |
| 1148 | IBM01148 | IBM EBCDIC International (500 + Euro symbol); IBM EBCDIC (International-Euro) |
| 1149 | IBM01149 | IBM EBCDIC Icelandic (20871 + Euro symbol); IBM EBCDIC (Icelandic-Euro) |
| 1200 | utf-16 | Unicode UTF-16, little endian byte order (BMP of ISO 10646); available only to managed applications |
| 1201 | unicodeFFFE | Unicode UTF-16, big endian byte order; available only to managed applications |
| 1250 | windows-1250 | ANSI Central European; Central European (Windows) |
| 1251 | windows-1251 | ANSI Cyrillic; Cyrillic (Windows) |
| 1252 | windows-1252 | ANSI Latin 1; Western European (Windows) |
| 1253 | windows-1253 | ANSI Greek; Greek (Windows) |
| 1254 | windows-1254 | ANSI Turkish; Turkish (Windows) |
| 1255 | windows-1255 | ANSI Hebrew; Hebrew (Windows) |
| 1256 | windows-1256 | ANSI Arabic; Arabic (Windows) |
| 1257 | windows-1257 | ANSI Baltic; Baltic (Windows) |
| 1258 | windows-1258 | ANSI/OEM Vietnamese; Vietnamese (Windows) |
| 1361 | Johab | Korean (Johab) |
| 10000 | macintosh | MAC Roman; Western European (Mac) |
| 10001 | x-mac-japanese | Japanese (Mac) |
| 10002 | x-mac-chinesetrad | MAC Traditional Chinese (Big5); Chinese Traditional (Mac) |
| 10003 | x-mac-korean | Korean (Mac) |
| 10004 | x-mac-arabic | Arabic (Mac) |
| 10005 | x-mac-hebrew | Hebrew (Mac) |
| 10006 | x-mac-greek | Greek (Mac) |
| 10007 | x-mac-cyrillic | Cyrillic (Mac) |
| 10008 | x-mac-chinesesimp | MAC Simplified Chinese (GB 2312); Chinese Simplified (Mac) |
| 10010 | x-mac-romanian | Romanian (Mac) |
| 10017 | x-mac-ukrainian | Ukrainian (Mac) |
| 10021 | x-mac-thai | Thai (Mac) |
| 10029 | x-mac-ce | MAC Latin 2; Central European (Mac) |
| 10079 | x-mac-icelandic | Icelandic (Mac) |
| 10081 | x-mac-turkish | Turkish (Mac) |
| 10082 | x-mac-croatian | Croatian (Mac) |
| 12000 | utf-32 | Unicode UTF-32, little endian byte order; available only to managed applications |
| 12001 | utf-32BE | Unicode UTF-32, big endian byte order; available only to managed applications |
| 20000 | x-Chinese_CNS | CNS Taiwan; Chinese Traditional (CNS) |
| 20001 | x-cp20001 | TCA Taiwan |
| 20002 | x_Chinese-Eten | Eten Taiwan; Chinese Traditional (Eten) |
| 20003 | x-cp20003 | IBM5550 Taiwan |
| 20004 | x-cp20004 | TeleText Taiwan |
| 20005 | x-cp20005 | Wang Taiwan |
| 20105 | x-IA5 | IA5 (IRV International Alphabet No. 5, 7-bit); Western European (IA5) |
| 20106 | x-IA5-German | IA5 German (7-bit) |
| 20107 | x-IA5-Swedish | IA5 Swedish (7-bit) |
| 20108 | x-IA5-Norwegian | IA5 Norwegian (7-bit) |
| 20127 | us-ascii | US-ASCII (7-bit) |
| 20261 | x-cp20261 | T.61 |
| 20269 | x-cp20269 | ISO 6937 Non-Spacing Accent |
| 20273 | IBM273 | IBM EBCDIC Germany |
| 20277 | IBM277 | IBM EBCDIC Denmark-Norway |
| 20278 | IBM278 | IBM EBCDIC Finland-Sweden |
| 20280 | IBM280 | IBM EBCDIC Italy |
| 20284 | IBM284 | IBM EBCDIC Latin America-Spain |
| 20285 | IBM285 | IBM EBCDIC United Kingdom |
| 20290 | IBM290 | IBM EBCDIC Japanese Katakana Extended |
| 20297 | IBM297 | IBM EBCDIC France |
| 20420 | IBM420 | IBM EBCDIC Arabic |
| 20423 | IBM423 | IBM EBCDIC Greek |
| 20424 | IBM424 | IBM EBCDIC Hebrew |
| 20833 | x-EBCDIC-KoreanExtended | IBM EBCDIC Korean Extended |
| 20838 | IBM-Thai | IBM EBCDIC Thai |
| 20866 | koi8-r | Russian (KOI8-R); Cyrillic (KOI8-R) |
| 20871 | IBM871 | IBM EBCDIC Icelandic |
| 20880 | IBM880 | IBM EBCDIC Cyrillic Russian |
| 20905 | IBM905 | IBM EBCDIC Turkish |
| 20924 | IBM00924 | IBM EBCDIC Latin 1/Open System (1047 + Euro symbol) |
| 20932 | EUC-JP | Japanese (JIS 0208-1990 and 0212-1990) |
| 20936 | x-cp20936 | Simplified Chinese (GB2312); Chinese Simplified (GB2312-80) |
| 20949 | x-cp20949 | Korean Wansung |
| 21025 | cp1025 | IBM EBCDIC Cyrillic Serbian-Bulgarian |
| 21027 | (deprecated) | |
| 21866 | koi8-u | Ukrainian (KOI8-U); Cyrillic (KOI8-U) |
| 28591 | iso-8859-1 | ISO 8859-1 Latin 1; Western European (ISO) |
| 28592 | iso-8859-2 | ISO 8859-2 Central European; Central European (ISO) |
| 28593 | iso-8859-3 | ISO 8859-3 Latin 3 |
| 28594 | iso-8859-4 | ISO 8859-4 Baltic |
| 28595 | iso-8859-5 | ISO 8859-5 Cyrillic |
| 28596 | iso-8859-6 | ISO 8859-6 Arabic |
| 28597 | iso-8859-7 | ISO 8859-7 Greek |
| 28598 | iso-8859-8 | ISO 8859-8 Hebrew; Hebrew (ISO-Visual) |
| 28599 | iso-8859-9 | ISO 8859-9 Turkish |
| 28603 | iso-8859-13 | ISO 8859-13 Estonian |
| 28605 | iso-8859-15 | ISO 8859-15 Latin 9 |
| 29001 | x-Europa | Europa 3 |
| 38598 | iso-8859-8-i | ISO 8859-8 Hebrew; Hebrew (ISO-Logical) |
| 50220 | iso-2022-jp | ISO 2022 Japanese with no halfwidth Katakana; Japanese (JIS) |
| 50221 | csISO2022JP | ISO 2022 Japanese with halfwidth Katakana; Japanese (JIS-Allow 1 byte Kana) |
| 50222 | iso-2022-jp | ISO 2022 Japanese JIS X 0201-1989; Japanese (JIS-Allow 1 byte Kana – SO/SI) |
| 50225 | iso-2022-kr | ISO 2022 Korean |
| 50227 | x-cp50227 | ISO 2022 Simplified Chinese; Chinese Simplified (ISO 2022) |
| 50229 | ISO 2022 Traditional Chinese | |
| 50930 | EBCDIC Japanese (Katakana) Extended | |
| 50931 | EBCDIC US-Canada and Japanese | |
| 50933 | EBCDIC Korean Extended and Korean | |
| 50935 | EBCDIC Simplified Chinese Extended and Simplified Chinese | |
| 50936 | EBCDIC Simplified Chinese | |
| 50937 | EBCDIC US-Canada and Traditional Chinese | |
| 50939 | EBCDIC Japanese (Latin) Extended and Japanese | |
| 51932 | euc-jp | EUC Japanese |
| 51936 | EUC-CN | EUC Simplified Chinese; Chinese Simplified (EUC) |
| 51949 | euc-kr | EUC Korean |
| 51950 | EUC Traditional Chinese | |
| 52936 | hz-gb-2312 | HZ-GB2312 Simplified Chinese; Chinese Simplified (HZ) |
| 54936 | GB18030 | Windows XP and later: GB18030 Simplified Chinese (4 byte); Chinese Simplified (GB18030) |
| 57002 | x-iscii-de | ISCII Devanagari |
| 57003 | x-iscii-be | ISCII Bangla |
| 57004 | x-iscii-ta | ISCII Tamil |
| 57005 | x-iscii-te | ISCII Telugu |
| 57006 | x-iscii-as | ISCII Assamese |
| 57007 | x-iscii-or | ISCII Odia |
| 57008 | x-iscii-ka | ISCII Kannada |
| 57009 | x-iscii-ma | ISCII Malayalam |
| 57010 | x-iscii-gu | ISCII Gujarati |
| 57011 | x-iscii-pa | ISCII Punjabi |
| 65000 | utf-7 | Unicode (UTF-7) |
| 65001 | utf-8 | Unicode (UTF-8) |



















![Errore in LibreNMS: Python3 module issue found: ‘Required packages: [‘PyMySQL!=1.0.0’, ‘python-dotenv’, ‘redis>=4.0’, ‘setuptools’, ‘psutil>=5.6.0’, ‘command_runner>=1.3.0’]](https://www.raffaelechiatto.com/wp-content/uploads/2024/09/Errore_in_LibreNMS_Python3_module_issue_found-1080x675.png.avif)
















0 commenti